Pandas.DataFrame
read_csv関数とインターネットからの読み込み
pandas.read_csv関数で読み込むと, DataFrameという形式で読み込んでくれる.このDataFrameは2次元の表に「行と列,それぞれにラベルがついている」データ形式であり,さらに複数のデータ型,例えば整数や実数,文字列を,一つの表の中に混在させることができる.(ただしもちろんデータとしてまとまりがなければならないので,行か列のどちらかでデータ型は揃っている必要はある)
また,インターネット上にあるファイルも直接読み込むことができる.この時「文字コード」と呼ばれる「日本語を扱うための形式」を指定する必要がある.
import pandas as pd
dataframe = \ # 改行の時はバックスラッシュ(半角円マーク)を入れると次の行のインデントは無視され,1つの行として扱われる.
pd.read_csv('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2506.csv', \
encoding='shift-jis')
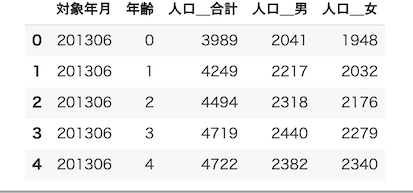
dataframe.head()
DataFrameオブジェクトのhead関数は,わかりやすく頭の部分だけを出力してくれる.各コードセルの「最後の行」で実行すること.もちろんhead関数の結果を変数に代入し,print関数に入れてやれば,セルのどこでも可能だが,Google Colaboratory上では(セルの最後の行で実行したようには)色分けはされない.
ちなみに,Google Colaboratoryではなく,Anaconda等で自分のコンピュータでPythonを実行する時には,URLの部分をファイル名にしてやればよい.(大きいサイズのCSVの時には予めGoogle Colaboratoryにファイルをアップロードしておいて,そのファイル名で読み込むこともできる)
Pythonはインデントでブロックが決まるので,ただ改行しただけではプログラムが実行できなくなってしまう.そこで1行長すぎて改行したい時には,\を入れる.半角バックスラッシュは日本語キーボードでは半角の円マーク相当する.
文字コード
文字コードはencoding='shift-jis'の場所で指定している.通常,官公庁のオープンデータはCSVと呼ばれる「値がカンマで区切られたExcelのシートのような形式」のテキストファイルとして提供されているが,日本語Excelで作られたためか文字コードが「シフトJIS」という形式になっている.
Python3の標準の文字コードは「UTF-8(8bitにエンコードされたUnicode)」という形式であり,現在のWebページのほとんどこのUTF-8という文字コードを採用しているが,何故かExcelのCSV書き出しは文字コードをシフトJISで書き出し続けている.そこで官公庁データを読み込む時には文字コードを基本的にシフトJISだと覚悟して,encoding='shift-jis'をつけた方が良い.
列の値のラベルを使った取り出し
通常CSVは値だけが入っていることは少なく,1行目が「列の各項目の名前」になっていることが多い.この「列の名前」……つまり列のラベルを使った操作をpandas.DataFrame形式のデータでは行うことができる.
numpyは「値だけ」の行列だったのに対して,pandas.DataFrame形式では「列のラベル」(もちろん行のラベルもある)を使って操作できることに最大の特徴がある.
例えば,「その列の値だけ」を「その列のラベルを使って」取り出すことができる
locという関数(正確にはオペレータ)を使うが,
loc[:, '列のラベル']のように取り出す.
最初の:は「行は全部」(0~あるだけ)という意味.
loc[0:, '列のラベル']とも書ける.
dataframe.loc[1:3, '人口_男']と書くと,
'人口_男'列の「1行目から3行目」を抽出する,という意味になる.
(行番号は0から始まることに注意)
# それぞれ「列」に分解していく
# 年齢の「列」だけを,列のラベルを使って,1次元配列で取り出していく
age = dataframe.loc[:, '年齢']
population_man = dataframe.loc[:, '人口_男'] # このデータはアンダースコアが全角であることに注意
population_women = dataframe.loc[:, '人口_女']
population_sum = dataframe.loc[:, '人口_合計']
# データ形式を表示してみる
print(type(population_man)) # DataFrameの1次元版はSeriesと呼ぶ.ほぼnumpyと同じように扱うことができる
# 試しに中身の表示
print(population_man)
type関数に変数を入れることで,変数のデータ形式を確認することができる.ちなみにpandas.DataFrameから列だけを取り出した1次元配列はpandas.Seriesというデータ形式になっている.現在は,ほぼnumpy1次元配列と同じように扱うことができる.
明確にnumpyの1次元配列に変換したい場合,格納しているSeriesの変数名.valuesnumpy配列にアクセスできる.(関数ではないことに注意)
上記では,列にラベルがある場合を想定したが,もちろん行の方にラベルがあっても構わない.また両方とも行or列のインデックス指定(行番号指定,列番号指定)でも取り出せる.(loc[1:3, 4:6]は1行目~3行目かつ4列目~6列目を取り出す,という意味になる)
CSVのデータを基にグラフを描く
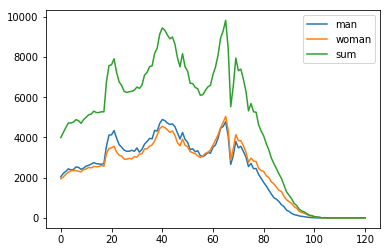
X軸とY軸に,取り出した列を与えて,折れ線グラフを描画する.
この場合X軸は年齢,Y軸は男性,女性,合計の年齢に対応する人口である. すでに前のセルで,列のデータを取り出してるので,それぞれの組を与えるだけで良い
# グラフ表示のライブラリmatplotlib.pyplot
import matplotlib.pyplot as plt
# X軸に年齢, Y軸にそれぞれの人数を入れる
# pandas.Seriesでもnumpyと同じように読んでくれる
# labelは凡例で表示される文字列.
# これをつけておかないと,どの色が何のデータを表しているのかわからなくなる.
plt.plot(age, population_man, label='man')
plt.plot(age, population_women, label='woman')
plt.plot(age, population_sum, label='sum')
# 凡例を表示させる
plt.legend()
#グラフを描画する
plt.show()Google Colaboratoryでのグラフ描画の結果は以下のようになる.
各種ライブラリのCSV読み込み機能
先の例ではpandasでCSVファイルを読み込んだが,実は他にも方法がある.しかしpandasのread_csvのようには便利ではないし,一度別のurllib.request.urlopen関数を使ってインターネットから取得する部分を別に書いてやる必要があったり,文字コードの読み込みに難があったりなどするため,現実的ではない.
標準csvライブラリcsv.reader()による読み込み
Python3の標準CSVライブラリは,
- 標準ライブラリの
codecs.open()関数で,文字コードを指定しつつファイルを開く csv.reader()関数で「データ本体を含むインスタンス」にする.ちなみにイテレータのインスタンスである.- イテレータのインスタンスなので,
next()関数,もしくはfor文で1行ずつ読んでいく.1行が1次元の文字列のlistとして出てくるので,処理をしつつ格納する. - 最後にファイルを
close()する.
という流れになる.
CSVファイル内に入っている「処理したい」ターゲットが文字列の場合,今の所この標準csvライブラリを使う方法が一番適当である.
numpy.loadtxt()による読み込み
numpyで読み込む場合,CSVの中身が数字である必要がある.
流れは標準csvライブラリと同じく,codecs.open()関数でファイルを開いて,2次元配列として一気に読み込み,close()する,という流れだが,「数字である」ことが前提なので,ヘッダ等の文字列で構成されている行をskiprows=行数と「何行読み飛ばすか」を指定してから読み込み始めなければならない.
またdelimiter='区切り文字'指定により,区切り文字を明示的に指定する必要がある.(CSVは区切り文字がTABのこともあるため)
pandas.read_csv()によるpandas.DataFrame形式での読み込み
先の通り,2019年現在は,pandasを使うのが一般的.
pandasも内部的にはnumpyの配列を使っているので,やはりnumpyの2次元配列で取り出すことができるが,もっと汎用性の高いDataFrame(データフレーム)という形式で読み込むことができる.(DataFrameがpandasの最大特徴である)
さらにpandasはCSVデータをDataFrameとして読み込む時,ヘッダを特殊扱いして文字列として取り出すことができる(もちろん後述のようにnumpyと同じくヘッダを最初から読み飛ばすしてもできる).
またnumpy.loadtxt()だと強制的にfloatのみになるが,pandas.read_csv()は全て整数だった場合intの配列を作ってくれる.
さらに,標準csvライブラリやnumpy.loadtxt()のようにファイルを最初にopenして読み込み後にcloseする必要がない,numpy.loadtxt()と同じく全てのデータを一気に2次元配列として持ってくることができるが,pandasのDataFrameは,列だけを1次元numpy配列として容易に抽出できる,キーワードを与えて行や列を持ってくることができる,等の特徴がある.
さらにCSV読み込みの時は,区切り文字は自動判定される.
pandasのDataFrameは,このように非常に便利なので,基本的にはpandasのread_csvを使うと良い.
pandas以外の方法のコード例
このコードは機能をまとめてクラス化しているので,Google ColaboratoryやJupyter Notebookのようにコード単位で逐次的に実行していくものではなく,複数を一気にダウンロードして描画するなど,バッチ的に一気に処理することができる.
もちろんpandasのみを使用するときでも,クラス化しておけば,このように一気に回すことができる.
# -*- coding: utf-8 -*-
# CSVPlotter.py
import csv, numpy, pandas
import urllib.request
import codecs
# ローカルのAnacondaのPythonでグラフウィンドウを出すためには,これが必要
from PyQt5.QtWidgets import QApplication
import matplotlib.pyplot
class CSVPlotter():
def __init__(self, url_string):
self.__url_string = url_string
def download_csv(self, decoder):
# 引数decoderで指定した文字コードのCSVファイルをダウンロードして,
# UTF-8に直して保存する
self.__gotten_http_response = urllib.request.urlopen(self.__url_string)
if self.__gotten_http_response.code == 200:
# コード200が返っていてきたら正常に取得できている
print('Sucsess to get CSV from Internet.')
# ダウンロードしてきたデータを一度ファイルに書き込む
self.__downloaded_filename = 'downloaded.csv'
downloaded_file = codecs.open(self.__downloaded_filename, mode='w', encoding='utf-8')
downloaded_file.write(self.__gotten_http_response.read().decode(decoder))
downloaded_file.close()
print('Sucsess to write downloaded CSV data to file.')
else:
# それ以外のコードが返ってきたら,異常終了
print('Cannot get CSV file. Code:', self.__gotten_http_response.code, 'Exiting...')
sys.exit(1)
def read_csv_with_csv(self):
# 標準ライブラリのcsvを使ってCSVファイルを読み込む
print('標準のcsvライブラリで読んで表示')
csv_file = codecs.open(self.__downloaded_filename, mode='r', encoding='utf-8')
self.__csv_data = csv.reader(csv_file)
# header以外は2次元のlistで出てくる
# 外側のlistがRow(行),
# 内側のリストがColumn(列)でデータ型は文字列
header = next(self.__csv_data)
# 1行目(データ本体ではなくデータの内容を示すヘッダ)
print(header)
for a_row in self.__csv_data:
print(a_row)
csv_file.close()
def read_csv_with_numpy(self):
# NumPyライブラリを使ってCSVファイルを読み込む
print('NumPyライブラリで読んで表示')
# NumPyの読み込みデータはNumPyの2次元array(ndarray)でくるので,分解して表示
# データ型はfloat
csv_file = codecs.open(self.__downloaded_filename, mode='r', encoding='utf-8')
self.__csv_data = numpy.loadtxt(csv_file, delimiter=',', skiprows=1)
csv_file.close()
# 区切り文字を','とし,1行目(ヘッダ)を抜かして読み込む
for a_row in self.__csv_data:
print(a_row)
def read_csv_with_pandas(self):
# Pandsライブラリを使ってCSVファイルを読み込む
print('Pandasライブラリで読んで表示')
data_frame = pandas.read_csv(self.__downloaded_filename)
# 文字列ヘッダが含まれててもエラーを起こさない
# ヘッダだけを取り出すことができる
header = data_frame.columns.values.tolist() #headerは標準list
self.__csv_data = data_frame.values
print(header)
# Pandsの読み込みデータもNumPyの2次元arrayでくるので,分解して表示
# データ型は,中身が整数ならintに変換される
for a_row in self.__csv_data:
print(a_row)
def make_plot_csv_data_2d(self, x_index, y_index, line_color):
# インデックスで指定されたX軸要素とY軸要素を使い
# NumPyのndarrayに入れて
# Matplotlib.plotで図を描く
plot_x_array = numpy.array([]) #空のnumpy ndarrayを生成
plot_y_array = numpy.array([])
for a_row in self.__csv_data:
if isinstance(a_row[x_index], str):
# numpy ndarrayに追加していく
plot_x_array = numpy.append(plot_x_array, float(a_row[x_index]))
else:
plot_x_array = numpy.append(plot_x_array, a_row[x_index])
if isinstance(self.__csv_data[y_index], str):
plot_y_array = numpy.append(plot_y_array, float(self.a_row[y_index]))
else:
plot_y_array = numpy.append(plot_y_array, a_row[y_index])
# plotに使うデータを設定
matplotlib.pyplot.plot(plot_x_array, plot_y_array, color=line_color)
def plot_show(self, x_label, y_label):
# plotの軸の名前を設定
matplotlib.pyplot.xlabel(x_label, fontsize=10, fontname='serif')
matplotlib.pyplot.ylabel(y_label, fontsize=10, fontname='serif')
# plotする
matplotlib.pyplot.show()
if __name__ == "__main__":
# 八王子市年齢別人口
# http://www.city.hachioji.tokyo.jp/contents/open/002/p005866.html
csv_url = "http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2703.csv"
csv_plotter = CSVPlotter(csv_url)
csv_plotter.download_csv('shift-jis')
csv_plotter.read_csv_with_csv()
csv_plotter.read_csv_with_numpy()
csv_plotter.read_csv_with_pandas()
csv_plotter.make_plot_csv_data_2d(1, 2, 'gray')
csv_plotter.plot_show('Age', 'Population Size')応用 - バッチ的に複数のCSVを処理して描画する
上記でクラス化した処理を使って,一気に複数をダウンロードし,描画する.
八王子市の年齢別人口データを年度/四半期ごとに複数持ってきて,一つのグラフに色を変えてプロットしてみる.
前述のコード例では,標準CSVライブラリで出てくるCSVのデータ形式に合わせて行ごとに読み込んだが,Google ColabやJupyterのコードのように,pandasのCSVライブラリで読み込むと,1列のみ簡単に取り出せることができる.また,ヘッダの行数を指定して読み込まない,等の処理が可能である.
コード例
# -*- coding: utf-8 -*-
# MultiCSVPlotter.py
import numpy, pandas
import urllib.request
import codecs
from PyQt5.QtWidgets import QApplication
import matplotlib.pyplot
class MultiCSVPlotter():
def __init__(self, url_string_list):
self.__url_string_list = url_string_list
# numpyのndarrayで多次元配列を作るためには
# np.array([])で初期化せずに(→append()しても連結された1次元配列になってしまう)
# np.arange(0, x軸の最大値+1)で0〜最大値までの配列を最初に作って(X軸になる),
# そこにvstack関数を使ってY軸になる配列を足していく形を取ると良い
self.__csv_data_array = numpy.arange(0, 121)
# 他のものも一応初期化しておく
self.__column_index = 0
return None
def set_referring_column_index(self, column_index):
# CSVファイルの何列目を見るか 0(1列目)~
self.__column_index = column_index
return self
def download_csv_then_push_stack(self, decoder):
# ShiftJISのCSVファイルのURL配列をダウンロードして,
# UTF-8に直して一時保存してから,
# pandasのCSV読み込み機能を使って読み込み,
# ndarrayに2次元配列として入れていく
for a_url in self.__url_string_list:
self.__gotten_http_response = urllib.request.urlopen(a_url)
if self.__gotten_http_response.code == 200:
# コード200が返っていてきたら正常に取得できている
print('Sucsess to get CSV from Internet.')
# ダウンロードしてきたデータを一度ファイルに書き込む
self.__downloaded_filename = 'tmp_downloaded.csv'
downloaded_file = open(self.__downloaded_filename, mode='w', encoding='utf-8')
downloaded_file.write(self.__gotten_http_response.read().decode(decoder))
downloaded_file.close()
print('Sucsess to download CSV data to file: ' + a_url)
print('Now start to read CSV as ndarray with pandas library.')
else:
# それ以外のコードが返ってきたら,異常終了
print('Cannot get CSV file. Code:', self.__gotten_http_response.code, 'Exiting...')
sys.exit(1)
# Pandsライブラリを使ってCSVファイルを読み込む
# ヘッダは読み込まない指定(header=-1)
# ヘッダは「1行」である指定(skiprows=1)
data_frame = pandas.read_csv(self.__downloaded_filename, header=-1, skiprows=1)
# まず取得した2次元配列の中から,column_indexで指定した列だけを抜き出す
# pandasは取得したCSV,ここではdata_frameに対して,
# data_frame[列idnex]でその列のみの
# 1次元配列をとり出せる.
populationSizeArray = data_frame[self.__column_index]
# できた1次元配列を,最初にX軸の配列で初期化した配列にvstack(())する.
# vstackは2重括弧であることに注意
# ただのstackでは同じ形(行と列が同じ量)の配列or行列同士しか足せないが,
# vstackは要素数が同じ1次元配列をどんどん重ねていき
# 多次元配列を作ることができる
self.__csv_data_array = numpy.vstack((self.__csv_data_array, populationSizeArray))
# ちなみにvstackの他に,hstack, column_stack, row_stackなどがある
# これを,CSVファイル数分だけ回す
print('Sucess to push new CSV column to stack')
return self
# return selfしないと,最後に実行した行の結果がreturnされるはず
# この関数の場合はそれでもいいのだけれど
def make_plot_csv_data_2d(self, line_color_list, line_legend_list):
# Matplotlib.plotで図を描く
# indexが1~shape(行列の次元数のtupleが得られる,ここでは(9, 121))[0]まで
for index in range(1, self.__csv_data_array.shape[0]):
# plotに使うデータを設定
matplotlib.pyplot.plot(self.__csv_data_array[0], self.__csv_data_array[index], color=line_color_list[index-1], label=line_legend_list[index-1])
#線に付与したlabel(凡例)を表示する
matplotlib.pyplot.legend()
def plot_show(self, x_label, y_label):
# plotの軸の名前を設定
matplotlib.pyplot.xlabel(x_label, fontsize=10, fontname='serif')
matplotlib.pyplot.ylabel(y_label, fontsize=10, fontname='serif')
# plotする
matplotlib.pyplot.show()
if __name__ == "__main__":
# 八王子市年齢別人口
# http://www.city.hachioji.tokyo.jp/contents/open/002/p005866.html
csv_url_list = list([])
# matplotlibで使える色のリスト
# http://matplotlib.org/examples/color/named_colors.html
# 一応16進数カラーコードでも指定はできる
line_color_list = list([])
# 凡例(線の色がどの年のデータを表しているか)
line_legend_list = list([])
# H25 6月
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2506.csv')
line_color_list.append('blue')
line_legend_list.append('H25.6')
# H25 9月
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2509.csv')
line_color_list.append('green')
line_legend_list.append('H25.9')
# H25 12月
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2512.csv')
line_color_list.append('red')
line_legend_list.append('H25.12')
# H26 3月 (「平成25年3月末日」tと書いてあるのは25年「度」3月末……の意味らしい)
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2503.csv')
line_color_list.append('cyan')
line_legend_list.append('H26.3')
# H26 6月
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2606.csv')
line_color_list.append('magenta')
line_legend_list.append('H26.6')
# H26 9月
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2609.csv')
line_color_list.append('yellow')
line_legend_list.append('H26.9')
# H26 12月
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2612.csv')
line_color_list.append('black')
line_legend_list.append('H26.12')
# H27 3月 (同様にH26年「度」3月末の意味のようだ)
csv_url_list.append('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2703.csv')
line_color_list.append('gray')
line_legend_list.append('H27.3')
csv_plotter = MultiCSVPlotter(csv_url_list)
csv_plotter.set_referring_column_index(2)
csv_plotter.download_csv_then_push_stack('shift-jis')
csv_plotter.make_plot_csv_data_2d(line_color_list, line_legend_list)
csv_plotter.plot_show('Age', 'Population Size')