Irisデータセット
機械学習の動作の確認などでよく使われるデータセット.3種類のアヤメの花弁の長さ,幅,萼の長さ,幅が収納されている.Rでは標準機能として搭載されており,irisという変数にdata.frame形式で収納されている状態で使える.すぐに読み込み動作確認を行うことができる.
列は「萼の長さ(Sepal.Length),萼の幅(Sepal.Width),花弁の長さ(Petal.Length),花弁の幅(Petal.Width)」の4種類があり、それにSpaciesという名前の列にアヤメの種類(setosa, versicolor, virginica)の「ラベル列」が1列ある.この場合の「ラベル」とは「この行のデータがどの種類(カテゴリ)に属するのか」を表すものである(数字が入っている場合,2種類の場合はダミー変数.2種類以上の場合はカテゴリ変数,とも呼ぶ).data.frame形式の「列名=ラベル」と混同しがちなので注意すること.
散布図
前回は折れ線グラフを書いたが,基本的には同じくplot関数を用いる.ltyを指定しなければ散布図になる.
Irisデータセットの読み込み
library(datasets)
data(iris)これを実行すると、irisという名前の変数にdata.frame形式でデータが入る。
print(iris)Jyputer Notebookではprintすると以下のように表示される.
散布図
Sepal.Length列とSepal.Width列をベクトル形式で取り出して,plot関数に入れるだけで,とりあえず散布図は描ける.この状態では全ての種類のアヤメが含まれている.
# x軸をSepal.Lengthに
x.array <- iris$'Sepal.Length'
# y軸をSepal.Widthに
y.array <- iris$'Sepal.Width'
#散布図を描く
plot(x.array, y.array, xlab='Sepal.Length', ylab='Sepal.Width')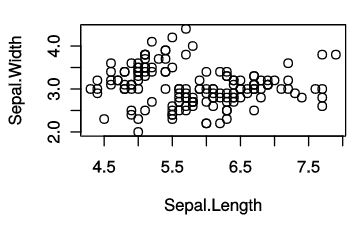
filter関数によるラベルごとに切り分け
先ほどただ散布図を書いただけでは,どの種類のアヤメも同じ描画をされていたので,これを種類ごとに別の表示にする.
statsパッケージのfilter関数を用いることで,容易にラベル列の文字列ごとに,ベクトルを切り分けることができる.(Rのバージョンが古いと,filter関数はdplyrパッケージに入っているようだ)
# 種類ごとに分けてplotする
# Speciesがアヤメの「種類」
# statsパッケージの中のfilter関数で,Species列の値(文字列)ごとに取り出す.
library(stats)
setosa <- filter(iris, Species=='setosa') # filter(元のdata.frame, ラベル列の列名=='ラベルの種類')
print(setosa)
printの結果を見ればわかるように,data.frame形式で抽出される.
ラベル列の列名はダブルクォーテーション,シングルクォーテーションで囲まない.(なぜこういう設計になっているのかはわからない)
同様に,versicolorとvirginicaも取り出す.
# 同じく versicolorとvirginicaも取り出す
versicolor <- filter(iris, Species=='versicolor')
virginica <- filter(iris, Species=='virginica')元のグラフに書き足す形で描画
Rのグラフの設計は,基本的には1回plot関数を呼び出したらグラフが描画されて,次にplot関数を呼び出された時はたらしいグラフを作る.これで3つの種類を一つのグラフの中に書けない.
そこで2つめと3つめの種類の描画の時には,その前にpar(new=TRUE)という関数を実行しておく.par関数はグラフィックパラメータの略のようで,new=TRUEは「既存のものに追加する」という意味である.(new=TRUE,つまり「新規=真」なので逆のようにも感じるが……)
さらなる注意点として,ラベルや軸の表示を3回ともやってしまうと,重なり合って汚く表示される.よって1回目もしくは3回目のみに軸の表示や軸ラベルを表示し,他のところでは明示的に軸の表示や軸ラベルを書かないように指定する.
このコード例では,3回目に軸の表示や軸ラベルを描画しているため,1回目と2回目の描画にはann=FALSEというオプションを入れて,軸や軸ラベルを表示しないようにしている.
さらに,軸のメモリも揃える必要がある.xlimとylimの値(これは軸の最小値と最大値をベクトルで指定する)を揃えてやる必要がある.
plot(setosa$Sepal.Length, setosa$Sepal.Width, col=2, xlim=c(3, 8), ylim=c(1, 4), ann=FALSE)
#xlimとylimを後の2つと揃える.ann=FALSEは軸ラベルを出力しない
par(new=TRUE) # この関数を実行すると,その後のplotは重ねて描画される
plot(versicolor$Sepal.Length, versicolor$Sepal.Width, col=3, xlim=c(3, 8), ylim=c(1, 4), ann=FALSE)
par(new=TTUE)
plot(virginica$Sepal.Length, virginica$Sepal.Width, col=4, xlim=c(3, 8), ylim=c(1, 4), xlab='Sepal.Length', ylab='Sepal.Width')
# 最後の描画でラベルを記入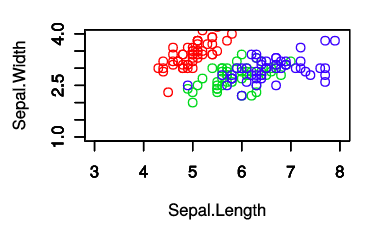
tapply関数による,種類ごとのデータの集計
ついでにtapply関数もこの項目でやっておく.apply関数は行や列ごとの集計,mapply関数は要素ごとの処理であったが,tapply関数は,この「ラベル列(カテゴリ変数)」ごとに,集計を行う関数である.
ついでにtapply関数
# グループごとに特定の処理をする関数.例えば......
# 与えられたベクトルの平均を求める関数を定義しておく
get.mean <- function(v){
return(sum(v) / length(v))
}
# 第1引数が,処理したい列,第2引数が種類が入っている列,第3引数が関数オブジェクト
sepal.length.mean <- tapply(iris$'Sepal.Length', iris$'Species', get.mean)
print(sepal.length.mean)
# つまり処理したい列が,種類が入っている列でグループ分けされて,ベクトルになり,関数に入る. setosa versicolor virginica
5.006 5.936 6.588 与えた関数オブジェクトには,Species列の種類ごとに切り分けられたSepal.Lengthの値がベクトルで入ってくる.その平均を出力している.