本項でもGoogle Colaboratoryを使用する.(もちろんファイル読み込みの部分以外はJupyter Notebookでもよいし,一気にPythonのソースコードをまとめて書いて実行しても問題はない)
異なる2地点以上の比較
前回のt検定は,2つの群の間で,統計的に本当に違いがあるかをいうためのものだった.,
今回は,1977年〜2018年の,青梅,八王子,府中の3箇所,つまり3群で違いがあるかを見る.
前回と全く同じ気象庁のオープンデータを使う.
分散分析(一元配置分散分析)とは
今回の場合は「3つ以上の地点の気温データ群の間の差を,統計的に(ある程度)保証してくれる」のが分散分析である.要するに3群以上の検定.
分散分析にもt検定と同じく,対応がある場合と対応がない場合があるので,前回を復習しておくこと.今回は対応がない場合のみを取り扱う.
Bartlett検定
t検定では,2群の分散(散らばり方)が等しい時とそうでない時で,適用する方法が違っていた.(Studentのt検定と,Welchのt検定)3群以上の場合に等分散性をみるのがBartlett検定である.
F検定と同じく,帰無仮説は「与えられた3群(以上)の分散は等質である」,対立仮説は「与えられた3群(以上)の分散は等質であるとは言えない」である.したがって結果のp値の見方も同じく,0.05以上であれば帰無仮説が棄却されず「分散が糖質である」となる.
データの形式:アンスタック形式とスタック形式
scipy.statsを使う場合,t検定と同じように「一つの群を1次元配列として食わせてやる」形で動作するが,statsmodelsの標準の分散分析およびBartlett検定はそれとは異なり「値とラベルがペアになったものがたくさんある」というデータ形式で与えなければならない.ここでいう「ラベル」とは,この値がどの群のものなのか,を表す.
気温の配列は全部繋げた上で,観測地点ラベルの配列も作り,それを2次元配列にまとめる.その後次元を変更し 「気温と観測地点ラベルが対応したペアが,126個存在する」という感じに変更する.
このような,値とラベルが順不同で積み重なっているデータ形式を「スタック形式」という.それに対して先に作った表のデータは「アンスタック形式」と言う.表にするとわかりやすい.
アンスタック形式のデータのイメージ
| 江戸川 | 青梅 | 八王子 |
|---|---|---|
| 3.1 | 0.7 | 0.9 |
| 5.4 | 2.6 | 2.9 |
スタック形式のデータのイメージ
| 気温 | 地点ラベル |
|---|---|
| 3.1 | 江戸川 |
| 0.7 | 青梅 |
| 0.9 | 八王子 |
| 5.4 | 江戸川 |
| 2.6 | 青梅 |
| 2.9 | 八王子 |
スタック形式データの作成
Googleスプレッドシートで「スタック形式」のデータを作成する.
1月のCSVファイルを読み込んだ状態.CSVファイルはt検定で使ったものと同一である.
スプレッドシート本体のファイル名を変更しておく.
シートの名前も変更しておく.
t検定の時と同じように,不要な行列を削除する.
今回は,青梅,八王子,府中の3箇所を比較するので,それ以外の列は削除.
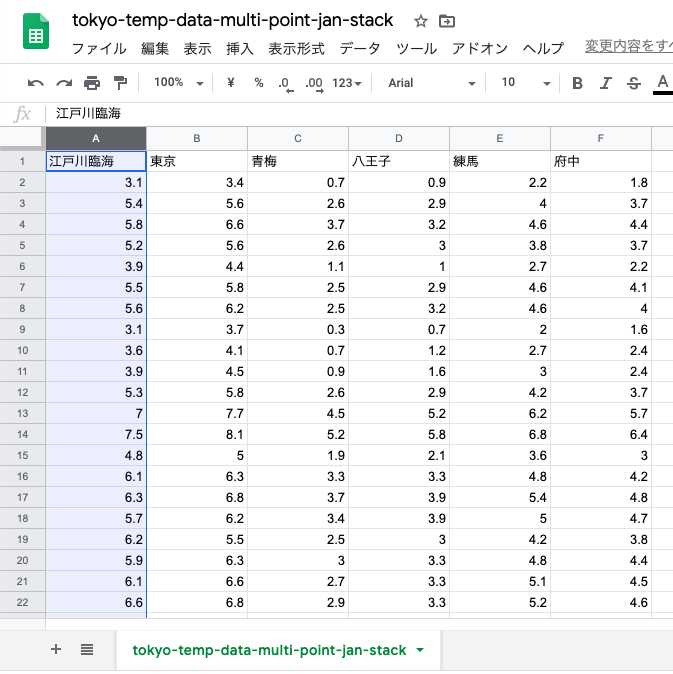
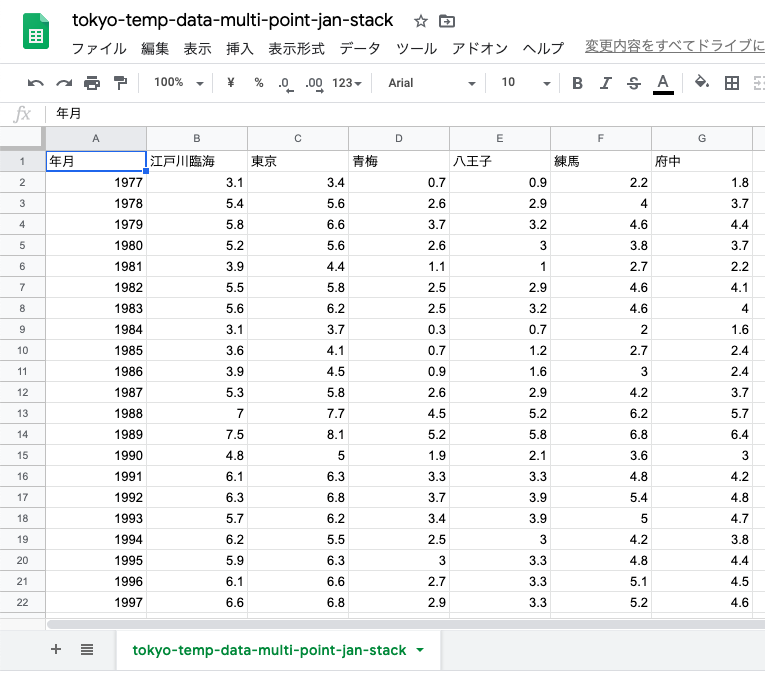
青梅,八王子,府中だけが残った状態.これは「アンスタック形式」.
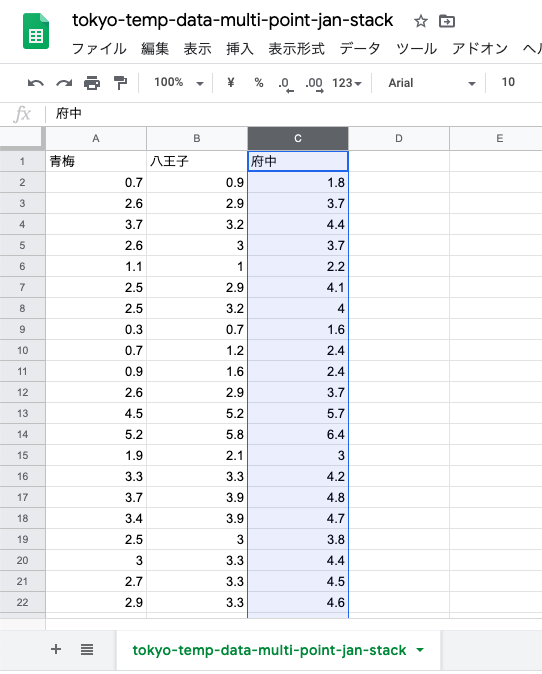
一番上に行を挿入.ここに新しい列名を入れる.
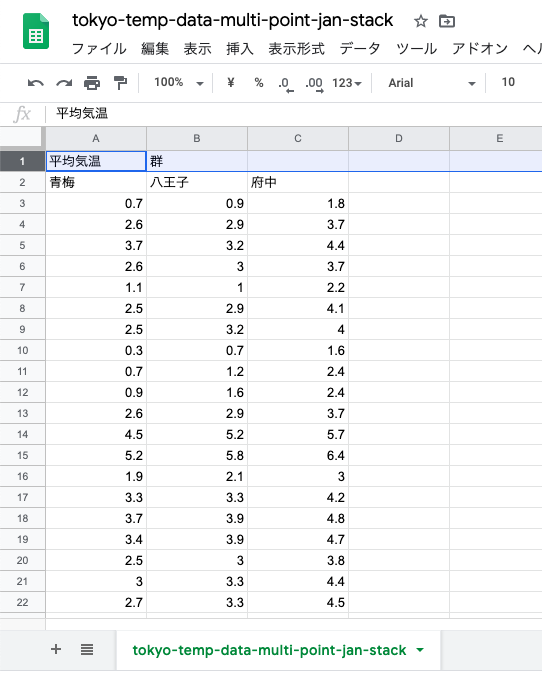
「値」の列名として「平均気温」,地点ラベルの列名は「群」にする.
八王子の1977年〜2018年を「切り取り」
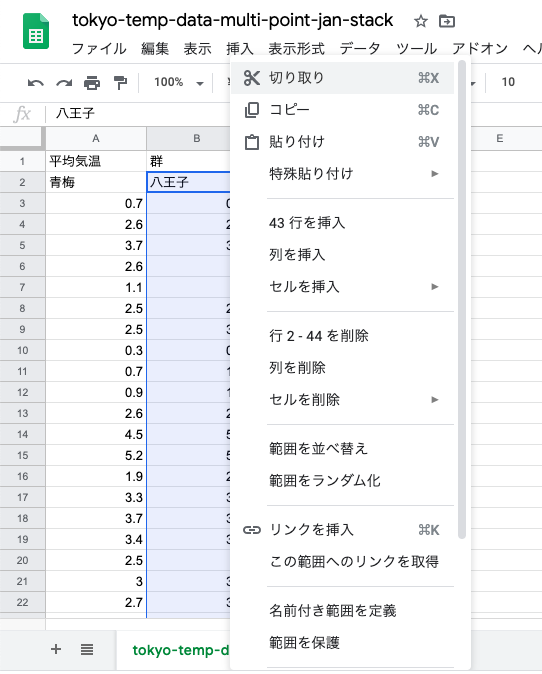
青梅の下(2018年の下)に「貼り付け」
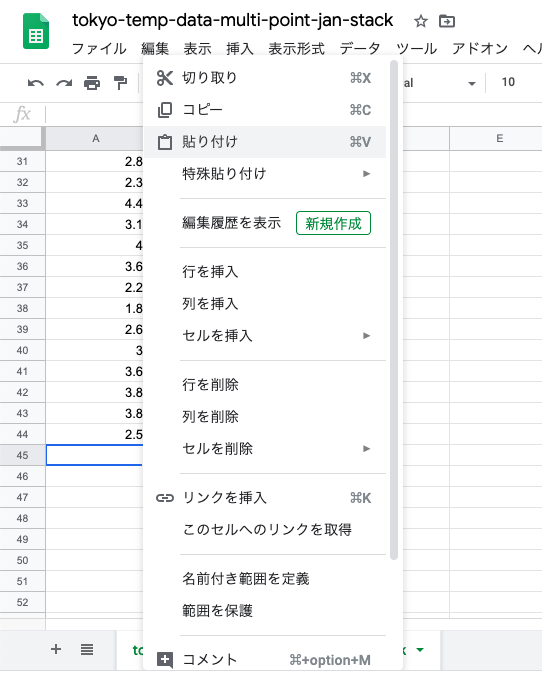
青梅と八王子の平均気温が1列に「スタック」(積み重ね)された.
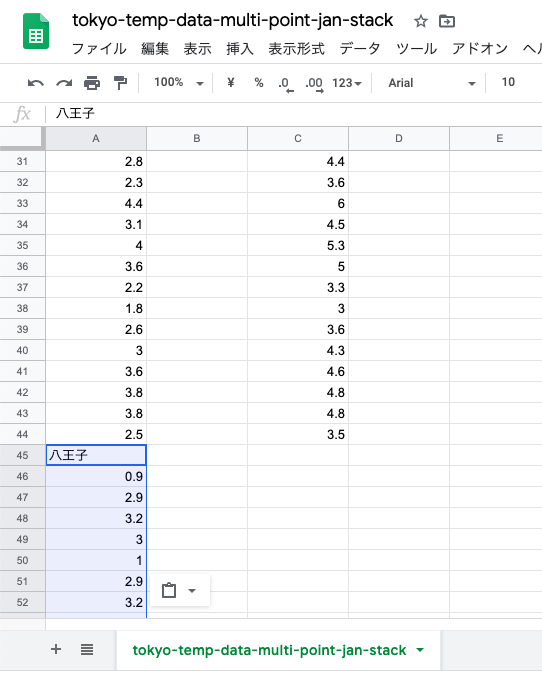
同じく府中のデータも切り取って,
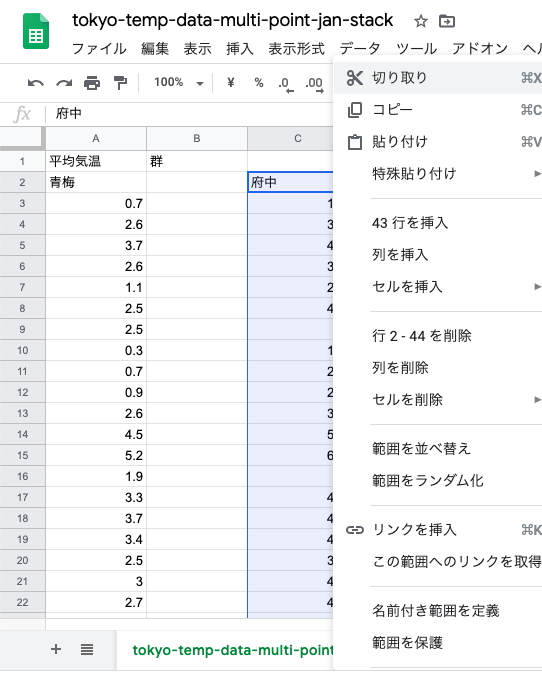
八王子のデータの下に貼り付け.
青梅と八王子と府中の平均気温が1列に「スタック」された.
「青梅」というセルを「コピー」して,
青梅の値が入っている一つ右,つまり1977年〜2018年の一つ右のセルを選択して,「貼り付け」
青梅の値である「平均気温」と,群ラベルである「地点」がセットになった.
同じように,八王子と府中の群ラベルもコピーして,群ラベルを完成させる.
元々の列名があった行,つまり「青梅」だけが入っている3行を削除.
同じように「八王子」だけが入っていた元々の列名があった行を削除.
府中も削除
そうしたら,同じようにCSV形式で「Webに公開」しておく.
import numpy as np
import pandas as pd
df = pd.read_csv('公開したURL')
df.head()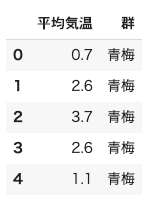
一応print(df)して,後ろの方まで見ておくと,

126 row x 2columnsと表示されているので,42年分3地点はちゃんと入っているっぽい.
Bartlett検定の実行
Pythonで明確にBartlett検定を実行できるのは,scipy.stats.bartlett関数である.残念なことにこの関数はアンスタック形式のデータ,すなわち群ごとのnumpy配列を取るようにできている.せっかくスタックデータを作ったが,切り出してnumpy配列にする.
pandas.DataFrameを,loc関数で切り出すと,出力は1列だけの時はpandas.Series,2時限以上の時はpandas.DataFrameで出力される.そのオブジェクトの中のvalues変数の中にnumpy配列が入っているので,それを取り出せば良い.
# Bartlett検定
import scipy.stats
# scipyのbartlett検定は,t検定の時のように,群ごとのnumpy配列を取る.
# つまり,42個ずつの「平均気温」だけの値が入ったnumpy配列を作成すれば良い
# pandas.DataFrameは取れないことに注意
# (アンスタックデータでは列だけ取り出せば良いので簡単だが,今回はスタック形式にしたので,ちょっと操作をする)
ome_ave = df.loc[0:41, '平均気温'].values # 平均気温列の0行目〜41行目を取り出すと,そのオブジェクトの中のvalues変数にnumpy配列が入っている
hachioji_ave = df.loc[42:83, '平均気温'].values
fuchu_ave = df.loc[84:, '平均気温'].values
bartlett_result = scipy.stats.bartlett(ome_ave, hachioji_ave, fuchu_ave)
print(bartlett_result)結果は以下のようになる.
BartlettResult(statistic=0.009294251494411373, pvalue=0.9953636554346814)Bartlett検定の帰無仮説は「分散は等質である」,対立仮説は「分散は等質とは言えない」である.
p値(pvalue)が0.99なので帰無仮説は棄却されず「3つの地点の1月の平均気温の分散は等質である」ということになり,分散分析を行うことができる.
分散分析の実行
dataオプションにはそのままスタック形式のDataFrameが入れば良いが,問題はformulaオプションである.
olsという関数が登場している通り,実はここで線形回帰をやっている.想像がつくかと思うが,'平均気温 ~ 群'というのは「Y(平均気温) = aX(群) + b」という式を省略して表記したものである.
つまり目的変数が「平均気温」,説明変数が「群」の線形回帰をやっている.
import statsmodels.api as sm
import statsmodels.formula.api as smf
# formula(式)を与えて線形回帰を呼び出す
ols_lm = smf.ols(formula='平均気温 ~ 群', data=df).fit()
# 線形回帰の結果をもとにType2の分散分析をかける
anova_result = sm.stats.anova_lm(ols_lm, typ=2)
print(anova_result)結果は以下の通り.
sum_sq df F PR(>F)
群 39.003333 2.0 15.758491 8.074710e-07
Residual 152.216667 123.0 NaN NaN群という説明変数のPR(>F)というのがp値.結果は8.07e-07なので,十分に小さく,帰無仮説「3つの地点の1月の平均気温には差がない」が棄却された,つまり「3つの地点での1月の平均気温には差がある」と言うことができる.
多重検定
この「有意差が出た」時点で平均だけを見て「全部の地点で差がある!」といってしまいがちだが,そうではなく「どこか1つ以上の地点で差がある」だけである.
分散分析自体は,どの群とどの群に差があるのかを出してくれないため,それを見つけるために多重検定というのを行う.
全ての地点を「クロス」で検定するみたいな言葉のイメージで,一番簡単なのが「分布の調整による多重比較法であるTukey-Kramerの多重検定」と呼ばれる手法である.
「Tukey-Kramerの多重検定」は,「各群の母分散も等しい(分散の等質性)」時につかえる.各群のサイズが等しくなくてもよい(この場合だと全ての地点が42個で同じサイズだが).
「各群の母分散も等しい」とは,簡単に言えば「全ての地点の気温データのばらつきの形が,だいたい同じ」と思っておくと良い(これは統計的にも確かめることができる.母分散の定義は「母集団の特徴を表す母数」参考: 母分散と不偏分散)
ちなみに名前の似ている「Tukeyの方法」という多重検定方法もあるが,これは各群のサイズが同じである必要がある.(pythonのstatmodelsの中に入っているのはTukey-Kramerらしいので,気にせず使える.TukeyHSDの「HSD」は,Honestly Significant Differenceの略で,Tukey-Kramerの別名)
statsmodelsの中のTukey-Kramerは,スタック形式のデータを扱うが,DataFrameを直接入れるのではなく,平均気温のnumpy配列と,群つまりラベルの配列に分けて入れなければならない.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
tukey_result_jan = pairwise_tukeyhsd(df.loc[:, '平均気温'].values, df.loc[:, '群'].values)
print(tukey_result_jan)結果は以下の通り.
Multiple Comparison of Means - Tukey HSD, FWER=0.05
===================================================
group1 group2 meandiff p-adj lower upper reject
---------------------------------------------------
八王子 府中 1.0095 0.001 0.4336 1.5855 True
八王子 青梅 -0.2881 0.465 -0.8641 0.2879 False
府中 青梅 -1.2976 0.001 -1.8736 -0.7217 True
---------------------------------------------------この結果を見ると,八王子-青梅間のみが,調整p値(出力表中p-adj)が0.05を上回っており,「reject」がFalseになっている.
すなわち,八王子-青梅間は「同じ」という帰無仮説が棄却されなかったことになり,逆に八王子-府中間,府中-青梅間では棄却されていることから「1977年から2018年までの1月平均気温では,この3地点のみでは府中だけが有意に気温が高い」ということができる.
分散分析と多重比較
「多重比較の方でも有意差を出してくれるなら,多重比較だけやればいいのではないか?」という疑問が出てくる.
Tukey-Kramerは,分散分析とは内部計算が違う(分散分析はF統計量というものを用いているが,Tukeyの方法では用いていない)ために,「分散分析では有意差が出なかったが,Tukey-Kramer多重比較では有意差が出た」なんてこともありうるし,その逆,つまり「分散分析で有意差が出たが,Tukey-Kramer多重比較では有意差が出なかった」ということもありうる.特に群が増えてくるとTukey-Kramer多重比較では「帰無仮説の数が増えて有意になりにくくなる」.
つまり,分散分析と多重比較は完全に別のものであり,従属関係にはない.「分散分析で有意差がある→多重比較を行う」ではなく,両方を独立させて目的に応じて適用を考える必要がある.
t検定を3回やってはダメな理由
多重比較を使わずに,最初からt検定を3回やればいいのでは?と思うかもしれないが,これはやってはいけない.
青梅,八王子,府中で,2群間の検定をそれぞれ「青梅-八王子間」「八王子-府中間」「府中-青梅間」でそれぞれ「有意水準5%で行う」とすると,「この組み合わせの少なくとも1つは有意差がある」となる確率の計算式は以下のようになる.
1 - (1 - 0.05) * (1 - 0.05) * (1 - 0.05)つまり「0.05を基準に検定したつもりが実際には0.14で検定している」ことになってしまう.0.14の基準は0.05よりもはるかに甘いので「非常に甘く見ている」ということである.
これは当然「比較する群が増えれば増えるほど甘くなる」ということであるから,3群以上の場合は必ず分散分析と多重比較を行う.
二元配置分散分析
今回行なった一元配置分散分析は,前述の通りアンスタック形式の表で言えば以下のようになる.
| 青梅 | 八王子 | 府中 |
|---|---|---|
| 22.8 | 23.7 | 23.8 |
| 26.6 | 27.4 | 27.6 |
| 24.9 | 25.9 | 26.1 |
| 21.7 | 22.4 | 22.5 |
これに対し二元配置分散分析というものもあり,2つの要素の違いを見る.例えば観測地点の名称ではなく,観測時点でのその地点の天気で見ると,以下のようなデータを取り扱うことになる.(平均気温ではなく,その観測時の気温)
| 観測時の天気\観測地点 | 青梅 | 八王子 | 府中 |
|---|---|---|---|
| 晴れ | 26.6 | 27.4 | 27.6 |
| 晴れ | 26.6 | 27.4 | 27.6 |
| 雨 | 24.9 | 25.9 | 26.1 |
| 雨 | 21.7 | 22.4 | 22.5 |
これを分析する時には,以下の3点に注目することになる.
- 地点によって気温に違いはあるのか
- 天気によって気温に違いはあるのか
- 地点と天気の2つの要素による相乗効果はあるのか
この3つ目の「相乗効果」を「交互作用」と呼び,交互作用を分析するのがわざわざ天気を入れた理由であり,これを分析することが二元配置分散分析となる.
二元配置分散分析は前述したようにstatsmodels.stats.anova_lmを線形回帰したモデルに対して適用することで出すことができる.(復習しておくこと)