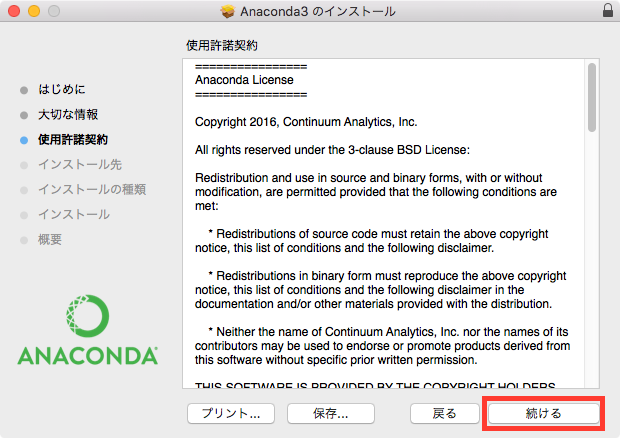
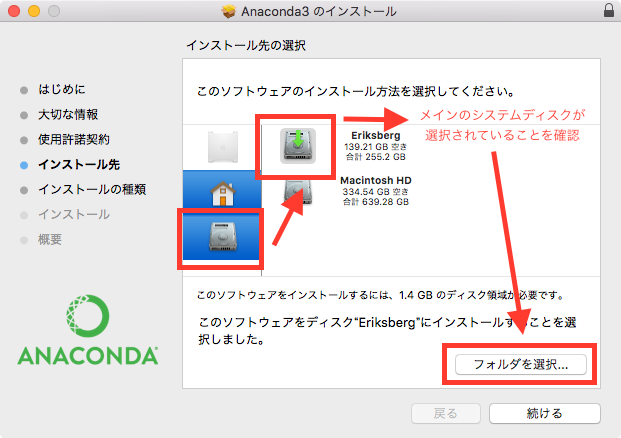
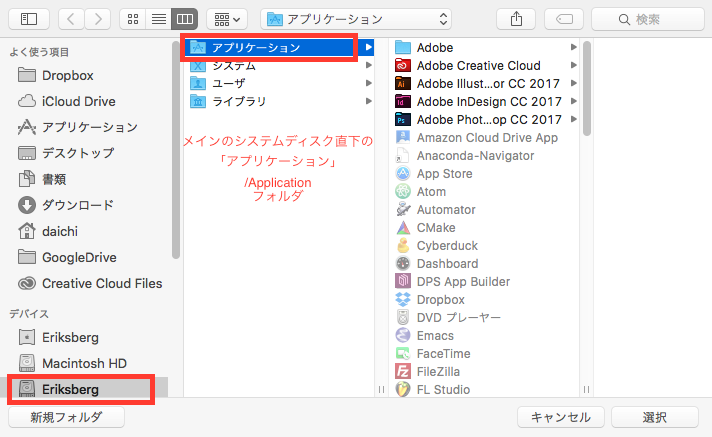
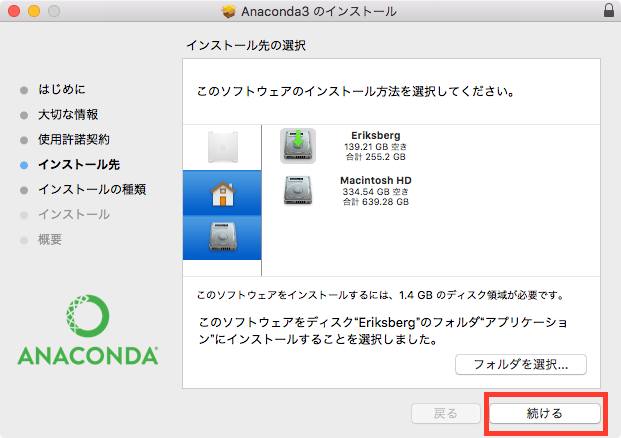
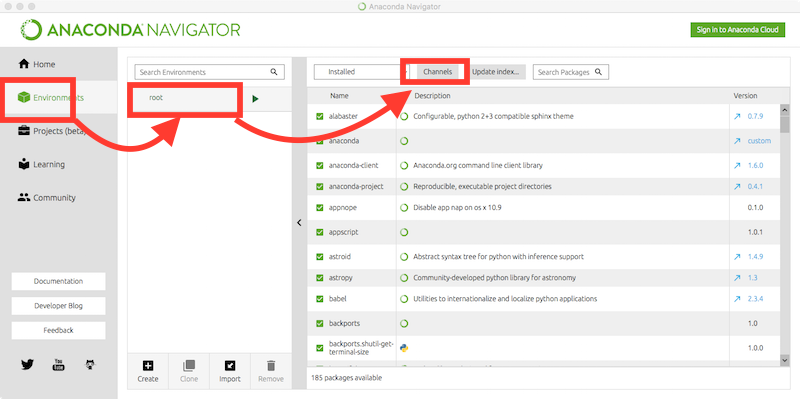
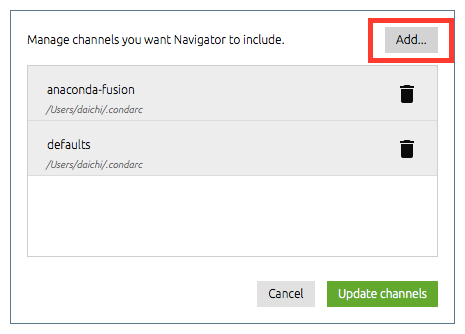
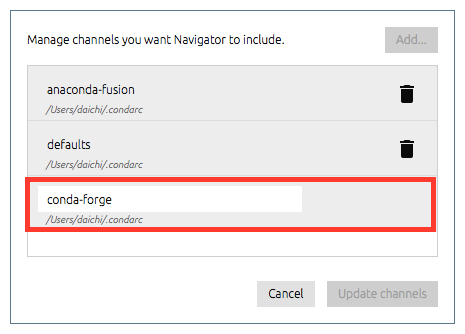
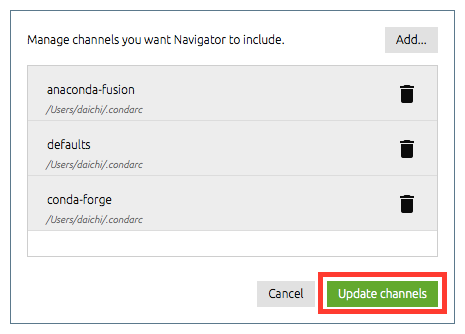
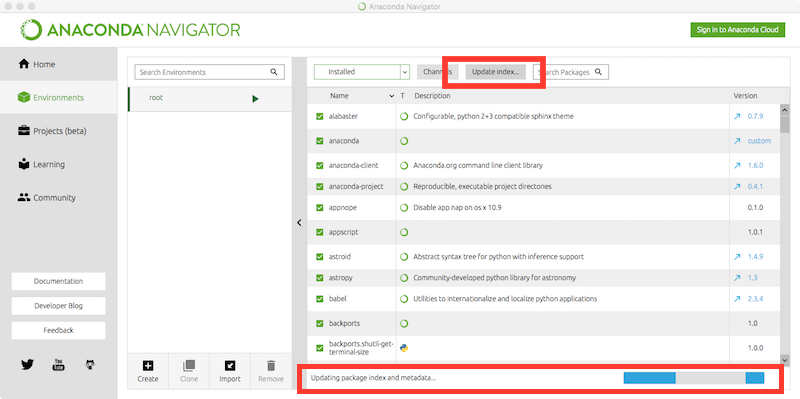
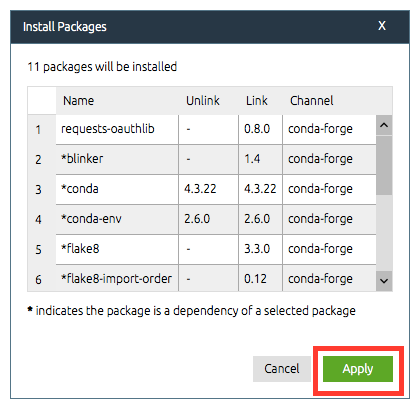
numpy
numpyは数字(int, float)等の配列をlistとは別の数字専用の配列で扱えるようにしたライブラリである.listとは違いC言語で書かれているため,NumPyのデータ型(数字の配列)numpy.ndarrayとnumpyに用意されている関数群を使えば,listで処理をするよりもはるかに早い計算ができる.
numpyは配列データ型ndarrayと,それを操作する静的クラス関数で構成されている.ndarrayのインスタンス関数はほぼない(インスタンス変数のshapeを使うぐらい)ので,C言語的な手続き型プログラミングのスタイルになる.
numpyの配列numpy.ndarray
numpyでは数字専用の配列numpy.ndarray(n次元配列)クラスが提供されており,そのインスタンスを用いることが前提のNumPyの関数群が用意されている.
ndarrayは一般的にコンストラクタ呼び出しで生成するのではなく,初期化用の静的クラス関数numpy.array(), numpy.empty(), numpy.zeros(), numpy.ones(), numpy.identity()などを使ってインスタンスを生成する.
numpyの配列はC言語と同じくサイズが固定されている(サイズを動的に弄れない).したがって,インスタンスを生成してくれるる静的関数.array()を呼び出す時に要素を全て入れるか,.empty()関数で形状(n x mの行列である,など)を指定する必要がある.また.empty()でデータタイプ(int, floatなど)も生成時に指定しておくと,実行時に予期せぬエラーが起きることが少なくなる.他に単位行列を作る.identity()関数もある.
import numpy
# 要素を入れてarray関数を呼び出す
my_numpy_array = numpy.array([1, 3, 5])
print(my_numpy_array)
# float型の10要素の空配列(1次元)を生成
my_numpy_array = numpy.empty(10, dtype=float)
print(my_numpy_array)
# emptyで生成すると,適当な値が入っていることがわかる
# float型0.0の要素で埋められた3x4の2次元配列(行列)を生成
# (3, 4)と中括弧で示すのはtupleの意味
my_numpy_array = numpy.zeros((3, 4), dtype=float)
print(my_numpy_array)
# int型の0の要素で埋められた2x6の行列を生成
my_numpy_array = numpy.zeros((2, 6), dtype=int)
print(my_numpy_array)
# int型の1の要素で埋められた3x4の行列を生成
my_numpy_array = numpy.ones((3, 4), dtype=int)
print(my_numpy_array)
# 4x4のfloatの単位行列を生成
# 単位行列は2次元配列であることが自明なので,
# tupleで(4,4)を与えずに1スカラ値変数だけでいける
my_numpy_array = numpy.identity(4, dtype=float)
print(my_numpy_array)
配列や行列の各要素へのアクセス
numpy_array[何番目か]という形で大かっこ[]を使ってアクセスする.
値を読みだすだけでなく,代入もできる.
my_numpy_array = numpy.array([1, 3, 5])
a = my_numpy_array[0] # 0番目,つまり最初の要素を取り出し,aに代入する
print(a)
my_numpy_array[2] = 7 # 2番目に7を代入する
print(my_numpy_array)
行列の場合は,numpy_array[行の番号][列の番号]という形で,大かっこを二つつなげてアクセスする.
my_numpy_array = numpy.identity(4, dtype=int) # 4*4の整数の単位行列の生成
print(my_numpy_array)
a = my_numpy_array[0][3] # 0行目3列目の要素を取り出し,aに代入する.
print(a)
my_numpy_array[2][2] = 6 # 2行目2列目に整数の6を代入する
print(my_numpy_array)
ndarrayのサイズを取得する
numpyの静的関数ndim()にndarrayのインスタンスを突っ込むと,n次元配列のnがわかる.
my_numpy_array = numpy.identity(4, dtype=float)
print(numpy.ndim(my_numpy_array)) # =>4x4の行列は2次元配列なので,出力は「2」
ndarrayのインスタンスが持つ.shape変数(tuple型)により,そのインスタンスの各次元のサイズを取得することができる.2次元配列の場合2要素のtupleなので,それぞれ[0]と[1]でアクセスする.
# 3要素の1次元配列を宣言
my_numpy_array = numpy.ones((3), dtype=int)
print(my_numpy_array.shape) # => (3, )
print(my_numpy_array.shape()[0]) # => 3
print(my_numpy_array.shape()[1]) #1次元配列なので,これはエラーになる
# 5x4要素の行列(2次元配列)を宣言
my_numpy_array = numpy.zeros((5, 4), dtype=int)
print(my_numpy_array.shape) # => (5, 4)
print(my_numpy_array.shape[0]) # => 5
print(my_numpy_array.shape[1]) # => 4
3次元配列なら3要素のtupleになるので,[0], [1], [2]でそれぞれアクセスする.
ndarrayに要素を追加する
ndarrayの静的関数としてappend()関数が用意されていて,複数の1次元配列を新たな1次元配列として連結することができる.
前述の通りndarrayのサイズは変更不可なので,append()関数で連結しても,第1引数に入れたインスタンスそのものが拡張されているわけではなく,新しいndarrayのインスタンスを返すだけなので,別の変数に代入する必要がある.
my_numpy_array = numpy.array([1, 3, 5]) # 要素1, 3, 5を持つ1次元配列のインスタンスを作成
new_my_numpy_array = numpy.append(my_numpy_array, numpy.array([7, 9, 11]))
print(new_my_numpy_array) # 連結された新しいndarrayのインスタンス
print(my_numpy_array) # もとのインスタンスは変更されていない
arange関数とndenumerate関数
標準listでいう所のrange関数に当たるのが,numpyの静的関数arange()である.使い方は同じ.
my_numpy_array = numpy.array(numpy.arange(10, 15, 0.1))
print(my_numpy_array)
またnumpy配列は,普通にfor文でも回せる.indexを取り出すときはnumpy.ndenumerate関数を使う.例えば,
numpy_array1 = numpy.arange(0, 10, 1) #0.0から10未満まで,1刻みで整数の配列を作る
numpy_array2 = numpy.zeros(10, dtype=int) # 0が10個入った1次元のnumpy配列
for index, val in numpy.ndenumerate(numpy_array1):
numpy_array2[index] = val + 10
print(numpy_array2)
# array1に10が足された[10 11 12 13 14 15 16 17 18 19]を出力する
という感じでfor文を書く.
numpy.ndenumerateは1次元のベクトルだけではなく,「行列にも対応できる」という点が非常に優れている.
2次元以上の場合にnumpy.ndenumerateを適用すると,indexはtuple,つまり数字の組み合わせで出てくる.大かっこでtupleを0番目(行),1番目(列)に分解する必要がある.
numpy_array1 = numpy.identity(4, dtype=int)
numpy_array2 = numpy.zeros((4, 4), dtype=int)
for index, val in numpy.ndenumerate(numpy_array1):
print(index) # tupleで出てきていることがわかる
row_index = index[0] # tupleを分解して,行のindexと列のindexの値にする
column_index = index[1]
numpy_array2[row_index][column_index] = val * 10
print(numpy_array2)
vstackによる1次元配列の積み重ねによる2次元配列の生成
例えば要素数10の配列が二つあるとして,これをもとに2x10の2次元配列(2x10の行列)を作りたい時,
my_numpy_array1 = numpy.array(numpy.arange(10, 15, 0.1))
my_numpy_array2 = numpy.array(numpy.arange(5, 10, 0.1))
print(numpy.vstack((my_numpy_array1, my_numpy_array2)))
とすると,作り出せる.vstack()関数は小括弧が二重であることに注意.(tupleを意味するので)
これまでと同じく,元の配列が拡張されるわけではなく,新たな行列のインスタンスが生成されて返される.
vstack()関数で,要素数が同じ配列なら,どんどん足していく(行列の行が増えていく)ことが可能である.例えば,
my_numpy_array = numpy.array(numpy.arange(1, 10, 0.1))
my_numpy_matrix = numpy.vstack((my_numpy_array, numpy.array(numpy.arange(2, 11, 0.1))))
my_numpy_matrix = numpy.vstack((my_numpy_matrix, numpy.array(numpy.arange(3, 12, 0.1))))
print(my_numpy_matrix) # => 3x90の行列ができている.
という感じである.
配列とスカラ値,もしくは配列同士の四則演算
配列に対してスカラ値(値が一つだけ入っている)変数を四則演算すると,各要素に対してそれが適用される
my_array = numpy.array(numpy.arange(1, 10, 2))
my_array_plus_2 = my_array + 3 # => [4 6 8 10 12]
my_array_minus_2 = my_array - 2 # => [-1 1 3 5 7]
同様に,要素数が同じ配列同士を四則演算すると,要素同士の四則演算となる.(行列演算ではないことに注意)
行列の演算
上記の計算は,配列の各要素に対して適用されるが,行列として掛け算をしたい(行列の積を求めたい)場合に静的関数の.dot()関数を使う.やはり他の変数で受けとらなければならない.
my_matrix1 = numpy.ones((4, 4), dtype=float)
my_matrix2 = numpy.identity(4, dtype=float)
my_matrix3 = numpy.dot(my_matrix1, my_matrix2)
同様にdot()関数を使うことで,ベクトル(つまり1次元配列)と行列(つまり2次元配列)の積も求めることができる.(これは2次元CGや3次元CGの座標変換などでよく使われる)
my_vector = numpy.array([1, 3.2, 5.6])
my_matrix = numpy.array([[4.2, 3.6, 2.5], [3.4, 8.9, 0.4], [0.2, 1.1, 0.5]])
print(numpy.dot(my_matrix, my_vector))
他の行列演算は,numpyのさらに中に定義されているクラスlinalgの静的関数を使う.こちらも静的関数である.
my_matrix = numpy.ones(4, dtype=float)
my_transposed_matrix = numpy.linalg.transpose(my_matrix) # 転置行列
my_inversed_matrix = numpy.linalg.inv(my_matrix) # 逆行列
my_eigenvalue = numpy.linalg.eig(my_matrix) # 行列の固有値
matplotlib
簡単に言えばグラフを書くためのライブラリである.バックエンドのGUIライブラリに何を使っているかは環境によって違うが,AnacondaやMSYS2のmingw64でインストールされるPython3用のmatplotlibでは,C++用のマルチプラットフォームGUIライブラリQtをPythonから使うための「PyQt」Ver.5が用いられている.
線のグラフ
2次元の線のグラフ(例えば折れ線グラフ,直線グラフ)を書くための手順を簡単に言えば,「X軸とY軸のnumpy配列をそれぞれ1次元のnumpy配列で作り,plot()関数で値の配列をセットし,show()関数で表示する.」だけである.
以下の例では3次関数 f(x) = -2x^3 + 8x^2 + 5を描画している.
まず線を引く際に基準となるX軸の範囲を,0から0.99の範囲まで0.01刻みで作成する.これはrange関数のnumpy版であるnumpy.arange関数を用いる.
x_asis_array = numpy.array(numpy.arange(0, 10.0, 0.01))
次に,この3次関数のyすなわちf(x)を計算する.
まず,x軸の要素数と同じy軸のnumpy配列を作る.numpy.zeros_like()関数は,与えたnumpy配列と同じ要素数で中身が全て0の配列を作るので,x_axis_arrayを与えて,numpy配列を生成する.
# x座標用と同じ要素数のゼロ配列を作る
y_axis_array = numpy.zeros_like(x_axis_array)
for文で,先ほどnumpy.arange関数を利用して作った,X軸用の値を格納しているx_asis_arrayから1つずつ値を取り出して,この計算式に入れればよいのだが,ここでnumpyの最大の特徴である「numpy配列の要素同士をまとめて計算できる」特徴を有効活用できる.
y_axis_array = -2 * numpy.power(x_axis_array, 3) + 8 * numpy.power(x_axis_array, 2) + 5
numpy.power(x, y)関数は,numpy配列の要素同士を一気に計算してくれる.1行の中(Pythonでは「式」と呼称する)に書くのであれば,上記のように複数の項があっても同時に計算してくれる.
Y軸の計算とnumpy配列の生成を1行で行う事もできる.この方法の方が要素数を間違えるなどのミスが少ないので,積極的に使うと良い.
y_axis_array = numpy.array(-2 * numpy.power(x_axis_array, 3) + 8 * numpy.power(x_axis_array, 2) + 5)
これは中身としては,for文を回すのと同じ事になる.例えば,
for x_value in x_axis_array:
y_value = -2 * x_value **3 + 8 * x_value **2 + 5
の計算をしているのと同じことになる.
numpyにはndenumerateというenumerateのnumpy版も存在し,以下のような書き方もできるようになる.(for文を回すとなると,for文を回す前にy_axis_arrayの初期化が必要になり,このようにインデックスを使わなければ代入できないので,実際は以下のコードでないと処理が書けない)
y_axis_array = numpy.zeros_like(x_axis_array) # Y軸の配列の0初期化
# listのenumerateのnumpy版.インデックスも同時に出してくれる.
for index, x_value in numpy.ndenumerate(x_axis_array):
y_axis_array[index] = -2 * x_value ** 3 + 8 * x_value ** 2 + 5
このX軸の値のnumpy配列とy軸の値のnumpy配列を,matplotlib.pyplot.plot()関数に入れて,matplotlib.pyplot.show()関数を実行すると,グラフが描かれる.
matplotlib.pyplot.plot(x_axis_array, y_axis_array, color='blue')
#'blue'は描画の線の色.省略可能.
matplotlib.pyplot.show()
ここまでのコードをまとめると以下のようになる.
# -*- coding: utf-8 -*-
import numpy
import matplotlib.pyplot
if __name__ == '__main__':
# x座標用の配列を作る
# 0から9.99までの1000要素
x_axis_array = numpy.array(numpy.arange(0, 10.0, 0.01))
# Y軸の配列をnumpyでまとめて計算して,Y軸の配列を作る
y_axis_array = numpy.array(-2 * numpy.power(x_axis_array, 3) + 8 * numpy.power(x_axis_array, 2) + 5)
# X軸とY軸をのデータをセットして描画する
# 2つの同じ要素数分の配列を与えると,基本的に折れ線グラフになる.
# 色指定もできる.
matplotlib.pyplot.plot(x_axis_array, y_axis_array, color='blue')
# 描画したウィンドウを見せる
matplotlib.pyplot.show()
折れ線グラフに関しては,特に意識することなくこの方法で描くことができる.試しにx軸の値の間隔を狭くして,折れ線グラフにしてみよう.
散布図
散布図を書くにはmatplotlib.pyplot.scatter関数を使う。
import numpy
import matplotlib.pyplot
x_axis_array = numpy.random.normal(loc=1.0, scale=0.5, size=100) # 平均1, 標準偏差0.5の正規分布に従う100個のランダムの値
y_axis_array = numpy.random.normal(1, 2, 100) # 引数を全て順番通りに指定するなら,どの引数に与える値なのかを省略できる
matplotlib.pyplot.scatter(x_axis_array, y_axis_array) # 散布図を描く
matplotlib.pyplot.show()
関数呼び出し時の引数の指定
numpy.random.normal関数は,平均と標準偏差を与えて,正規分布に従う乱数を指定した個数分生成する関数であるが,これまではなかった「どの引数に、どの値を与えるか」の指定をしている.
loc=やscale=,size=等の指定がそれである.「キーワード引数」と呼ぶ.
通常のプログラミング言語では,引数には順番があり,その順番通りに記述してやることで適切に引数を関数に渡すことができる.この場合,関数定義の時の引数の数と,関数を呼び出す時に与える引数の数が一致していなければならない.つまり基本的に同じ機能の関数であっても,引数の数が違う場合,複数の関数定義が必要となる.(関数のオーバーロードという仕組み)
一方,Pythonや最近の言語は,関数定義時に引数に名前を付けて,その名前を関数呼び出し時に指定することにより,引数の順番を任意に入れ替えることができる.(とはいえ,引数の順番はできるだけ揃えるべきである)
また標準で値が入らない引数,標準で値が入っている引数も指定することができ,普段は関数の中で標準で定められた値を使い,呼び出し側で引数で値を与えた時にのみその値をを使う,という形が実現できる.
Pythonで標準で使われるモジュールのほとんどの関数には引数に名前がついている.プログラムの分かりやすさを考えて,可能ならば引数の名前を指定した方が,可読性の高いプログラムを書くことができる.可読性が高いとは「誰が読んでもわかる」ということである.
import as
ここまで書いてくると,numpyだけならともかく,numpy.linalgクラスやmatplotlib.pyplotクラス内の静的関数を書くのが(文字数的に)面倒臭くなってくる.そこで,
import numpy as np
from numpy import linalg as la # numpyの中のlinalgクラスをimport……という意味
from matplotlib import pyplot as plt
とasキーワードを使ってimportすると,その名前(この場合はnpやla, plt)でそのクラスにアクセスできるようになる.
一般的にnumpyは「np」という名前で,linalgはlaという名前で,matplotlib.pyplotはpltという名前でimportされることが多いので,慣習に従うべきである.