本項でもGoogle Colaboratoryを使用する.(もちろんファイル読み込みの部分以外はJupyter Notebookでもよいし,一気にPythonのソースコードをまとめて書いて実行しても問題はない)
東京の異なる2地点,同じ地点での1月と8月の気温
回帰分析の項と同じく,気象庁のオープンデータを使う.
今回は,1977年〜2018年の,江戸川臨海,東京,青梅,八王子,練馬,府中の5箇所の,1月の月平均気温データと,8月の月平均気温データをCSVとしてダウンロードしておく.
これをやるためには2つのファイルに分けるのが一番楽っぽいので,同時点で期間の月のところを変えて,2つCSVファイルをダウンロードする.
ダウンロードした状態は,それぞれ以下から参照すること.
t検定とは
今回は,東京湾の海風が吹き付ける江戸川区と,内陸の練馬区で,月平均気温が違うかどうかをみる.
小中学校までなら,単純に「1977年から2018年までの平均を出してそれを比較すれば良い」と考えるかもしれないが,回帰分析の項で見た様に,平均気温は年単位で周期的な動きを見せるなど,安定しておらず,単に平均をとって比較するだけでは「それが本当に正しいのか」には大きく疑問が出てしまう.
「2つの気温データ群の間の差を,統計的に(ある程度)保証してくれる」のがt検定である.
「絶対的な保証」ではないが,「ある程度は」保証してくれる,と考えると良い.
2つ群間の検定には,
- 2群間に対応がある場合(2つの変数の間に何らかの従属関係がある場合)
- 2群間に対応ない場合の2つ(2つの変数は全く独立)
の2つがある.
1.の「2群間に対応がある場合」は,例えば「食事の前の血糖値と食事後の血糖値との比較」を考えてみると良い.この場合,データとしては「Aさんの食事前と食事後」「Bさんの食事前と食事後」「Cさんの食事前と食事後」……という対になるデータが必要である.
気温で考えてみると「同じ年の(1月の)平均気温で,江戸川と練馬に差があるか」になる.
この場合,月平均気温データが年ごとにペア対応している必要がある.
ペアのデータはこんな感じ「1977年の練馬の1月の気温, 1977年の江戸川の1月の気温」,「1978年の練馬の1月の気温, 1978年の江戸川の1月の気温」,「1979年の練馬の1月の気温, 1979年の江戸川の1月の気温」……このように年ごとに違う地点が並んでいれば良い.(順番はちゃんと並んでいなくても良い)
帰無仮説と対立仮説,p値
この様な統計処理の場合,「否定したい」帰無仮説と,帰無仮説が否定されることで(ある程度)保証される対立仮説の2つで,仮説を定義する.
「観測地点により,年ごとに考えても平均気温に差がある」ことを示したい場合,帰無仮説が「地点での平均気温差がない」であり,その帰無仮説が否定されると(ある程度保証される)のが「観測地点での平均気温の差がある」である.
この「ある程度保証する」の「ある程度」を表すのが,検定の結果出てくるp値という値である.p値が0.05「以下」の時,「5%水準で,有意差がある」(つまり「差がある」)なんて言い方をする.一般的に5%が統計的に「差がある」という水準.これが10%になると「値は色々違うけれど,統計的に立ちかめてみると,実は大した差がない」ぐらいの感覚で捉えておくと良い.
内部計算的には信頼区間とかが出くるが,詳しい説明は統計の教科書を読むこと.
データの整え方
Googleスプレッドシートに,まず1月のCSVを読み込む
前回と同じように,不要な行と列を削除する.
列名を整える.前回やったように,長い列名だとRの標準のdata.frame形式では読み込めない.短く「地点.jan.ave」にしておく.
「平均気温」の行も削除.
年月の列を「1977/1」から「1977」の形へ整える.「1977」年と「1978」年のセルの中身を変えて,
2年分を選択し,右下の四角を下に引っ張る.
それ以降の年が補完される.
同様に8月のCSVも別に読み込み,処理していく.
(処理すべきCSVシートが2枚以上で,同じ操作で整える場合,本来ならこの部分整える部分もプログラムで書いて自動化する.しかしRの標準のdata.frameではそれができない.data.frameを拡張したいくつかのクラスがあるので,それを使うと可能になる.Pythonは実質的に標準になっているpandas.DataFrameというライブラリで,同じ処理を複数のシートに対して行うことが得意なので,データが大量にある時はPythonの方が書きやすい.)
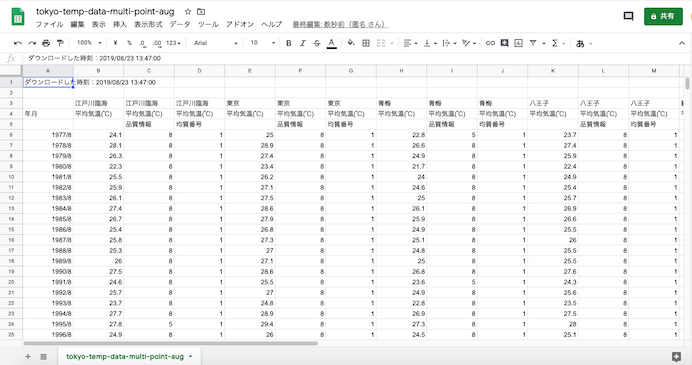
8月のシートのデータの部分だけを選択し,右クリックから「コピー」
1月のシートの右端を選択し,右クリックから「貼り付け」して,2つのシートをくっつける.
くっついた状態.列名が正しいことを確認する.(同じ列名だと読み込めない)
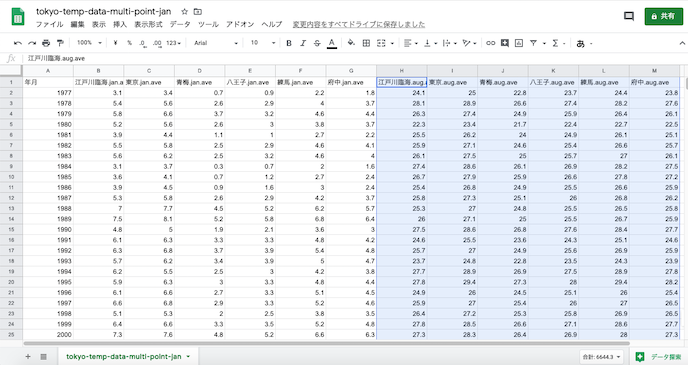
スプレッドシートのファイル名を「1月と8月両方入ってますよ」と変更し,

シートの名前も同じように変更する.
前々回,前回と同じように「ファイル」→「ウェブに公開」
公開するシートを選択し,カンマ区切り形式(CSV)を選択して公開し,URLをコピーしておく.
前々回,前回と同じように,以下のコードで読み込んで,最初の数行を表示する.
import numpy as np
import pandas as pd
df = pd.read_csv('公開したURL')
df.head()
欠損値
こうやって作成したdata.frameを最初の数行だけではなくprint(df)して,後ろの方までよく眺めると,2009年8月の江戸川臨海のデータが「NaN」となっており,「欠損」していることを発見できる.「2群間に関係性のないt検定」では問題は起きないが,「2群間に関係性のあるt検定では,2地点を比較した時に片方にだけ値がないと,エラーを起こす.
そこで「行を丸ごと」削除するという方法を取る.今回は1977年〜2018年と比較的長い期間なので,1年分ぐらいデータがなくても,まぁ大勢は変わらないだろう,という判断である.これが10年分のデータがないとなると,大きく影響が出るので,その場合は他の対策を考える.
df2 = df.dropna(how='any')と実行すると,欠損値が入っている行が丸ごと削除されて,df2という新しいDataFrame変数で受けることになる.
念のため,新しいDataFrameの次元数を確認すると,
print(df2.shape)
結果として(41, 13)が返ってくることから,1年分がまるっと削除されたことは間違いないようだ.
データ前処理と2群間に対応があるt検定のコード例
今は全ての地点の1月と8月のデータが1つのDataFrameに入っているが,,江戸川と練馬の1月と8月のNumpy1次元配列に,それぞれしておく.
#まず,江戸川と練馬のそれぞれ1月だけ,8月だけの配列を作る.
#それぞれ列を取り出して,データの次元を確認する
edogawa_jan = df2.loc[:, ['江戸川臨海.jan.ave']]
edogawa_aug = df2.loc[:, ['江戸川臨海.aug.ave']]
print('Edogawa Jan. shape:', edogawa_jan.shape)
# 1次元にする
edogawa_jan = edogawa_jan.values.flatten()
edogawa_aug = edogawa_aug.values.flatten()
# 次元を確認
print('Edogawa Jan. shape:', edogawa_jan.shape)
# 中身を確認
print(edogawa_jan)
# printした結果,中身が文字列なので,実数に変更
edogawa_jan = edogawa_jan.astype('float32')
edogawa_aug = edogawa_aug.astype('float32')
# 中身を確認する
print(edogawa_jan)
print(edogawa_aug)
print(edogawa_jan.shape)
print(edogawa_aug.shape)
# 練馬のデータも同じ様に処理する
nerima_jan = df2.loc[:, ['練馬.jan.ave']]
nerima_aug = df2.loc[:, ['練馬.aug.ave']]
nerima_jan = nerima_jan.values.flatten()
nerima_aug = nerima_aug.values.flatten()
nerima_jan = nerima_jan.astype('float32')
nerima_aug = nerima_aug.astype('float32')
print(nerima_jan)
print(nerima_jan.shape)
print(nerima_aug)
print(nerima_aug.shape)データが揃ったので,とりあえずそれぞれの平均を出してみる.
# データが揃ったので,とりあえず平均を出してみる
print('1977年から1988年までの1月の江戸川の平均気温', np.average(edogawa_jan))
print('1977年から1988年までの8月の江戸川の平均気温', np.average(edogawa_aug))
print('1977年から1988年までの1月の練馬の平均気温', np.average(nerima_jan))
print('1977年から1988年までの8月の練馬の平均気温', np.average(nerima_aug))4つ目のセルの出力は以下の様になる
1977年から1988年までの1月の江戸川の平均気温 5.597561
1977年から1988年までの8月の江戸川の平均気温 26.360973
1977年から1988年までの1月の練馬の平均気温 4.453658
1977年から1988年までの8月の練馬の平均気温 27.1170751977年〜2018年の間の月平均気温は,1月は江戸川の方が暖かく,8月は練馬の方が暑い,ということになる.
ここからt検定を行なっていく.5つ目のセル.「2群間に関係性のあるt検定」を行う.
同じ月の江戸川と練馬の平均気温のペアが必要であるが,並びが揃っている2つ1次元配列,すなわち2つの配列の同じ場所に比較したい同じ年の平均気温が入っている形で与えてやる.
それを検定にかける.
# 帰無仮説は「二つの集団の間に差がない」 = 「同じ年の江戸川と練馬の1月(8月)の月平均気温の間には,差がない」
# 対立仮説は「二つの集団の間に差がある」 = 「同じ年の江戸川と練馬の1月(8月)の月平均気温の間には,差がある」
# であり, 結果のp値が0.05を下回っていれば,「差がある」と見るべきである.
# この場合,
# 1. 同じ年で違う地点でのデータが,二つの地点の配列の並びの中で,同じ場所にある
# 2. 「何年」なのかは順不同になる.つまり古い順とか新しい順に並んでいる必要はない
# というデータの形にして食べさせれば良い
import scipy.stats
# これだけで検定を実行できる
result_jan = scipy.stats.ttest_rel(edogawa_jan, nerima_jan)
result_aug = scipy.stats.ttest_rel(edogawa_aug, nerima_aug)
#結果を出力する
print('同じ年の江戸川と練馬の1月の月平均気温の検定', result_jan)
print('同じ年の江戸川と練馬の8月の月平均気温の検定', result_aug)このセルの出力結果は以下の様になる.
同じ年の江戸川と練馬の1月の月平均気温の検定 Ttest_relResult(statistic=27.58108051178886, pvalue=1.203404241196893e-27)
同じ年の江戸川と練馬の8月の月平均気温の検定 Ttest_relResult(statistic=-11.70687214652232, pvalue=1.698531176507447e-14)pvalueがp値を指し,これは0.05よりもはるかに小さい.(e-27というのは,10の-27乗を掛ける,という意味である)
ということで,1月と8月双方において,年ごとに見ていって,「江戸川と練馬の気温には有意な差がある」と言うことができる.
2群間に対応がない場合のt検定とコード例
2群間に対応がない場合は,本当にただの値の集合2つの差を見る時に行われる.
先ほどは「年ごと」に対応させて検定したが,対応がない場合「(1977年〜2018年まで「全ての年をひっくるめて」)東京湾の海風が吹き付ける湾岸の江戸川は,風が吹き抜けない練馬に比べ)8月の平均気温が低い」という仮説を検証することになる.
(実際にt検定を行うときは,この「対応がない場合」がほとんどである)
先に出した平均気温を見た時に,確かに江戸川の方が練馬よりも8月の平均気温は低いが,それを統計的に保証するための検定をする.
この場合の,帰無仮説は「(1977年から2018年にかけての)江戸川と練馬の8月の月平均気温の間には,差がない」であり,対立仮説は「(1977年から2018年にかけての)江戸川と練馬の8月の月平均気温には差がある」である.
6番目のセルの内容は以下である.(1月もついでに行なっている)
# 次に「2群間に対応がない場合」を行う
# データが「等分散」というのは,母集団の数値の分散,つまり数値のばらつき方が同じか違うか,ということであり,
# 一般的には「等分散ではない」つまり二つの集団の数値のばらつき具合が異なっていても良い方法を使う
# 分散が同じ場合は「Studentのt検定」と呼び,
# 分散が異なる場合は「Welchのt検定」と呼ぶ
# 帰無仮説は「二つの集団の間に差がない」 = 「江戸川と練馬の1月の月平均気温の間には,差がない」
# 対立仮説は「二つの集団の間に差がある」 = 「江戸川と練馬の1月の月平均気温の間には,差がある」
# であり, 結果のp値が0.05を下回っていれば,「差がある」と見るべきである.
# これだけで実行できる
import scipy.stats
result_jan = scipy.stats.ttest_ind(edogawa_jan, nerima_jan)
result_aug = scipy.stats.ttest_ind(edogawa_aug, nerima_aug)
# 結果を出力する
print('1月の江戸川と練馬の月平均気温の検定', result_jan)
print('8月の江戸川と練馬の月平均気温の検定', result_aug)この6番目のセルの実行結果は以下の様になる.
1月の江戸川と練馬の月平均気温の検定 Ttest_indResult(statistic=4.6782503978085215, pvalue=1.1599005671463611e-05)
8月の江戸川と練馬の月平均気温の検定 Ttest_indResult(statistic=-2.477117763781257, pvalue=0.015352474172098927)結果の「statistic」はt統計量,pvalueがp値である.
8月のt検定のp値は0.015であり,0.05を十分に下回っているので,「差がない」帰無仮説は否定される,すなわち「(1977年〜2018年にかけての)8月の月平均気温は,江戸川の方が練馬よりも有意に低い」と言うことができる.
ただし,風が通っているからかどうかはこのデータからは当然わからない. 今回取得した他の「風が通る場所」と「風が通らない場所」を比較していくと,その可能性を検証できるかもしれない.試してみること.
ちなみに,scipyだけではなく,statsmodelsにも当然t検定はあり,全く同じように実行できる.結果の情報量は,statsmodelsの方が1つ多いので,statsmodelsを使う方がいいかもしれない.
statsmodelsの中の「対応がないt検定」を使ったコードは以下の通り.
# statsmodelsを使って,2群間に対応がないt検定を行う.
import statsmodels.stats.weightstats
result_jan = statsmodels.stats.weightstats.ttest_ind(edogawa_jan, nerima_jan)
result_aug = statsmodels.stats.weightstats.ttest_ind(edogawa_aug, nerima_aug)
print('1月の江戸川と練馬の月平均気温の検定', result_jan)
print('8月の江戸川と練馬の月平均気温の検定', result_aug)statsmodelsの中のttest_indを使った上記のコードの結果は以下のようになる.
1月の江戸川と練馬の月平均気温の検定 (4.678248968183461, 1.1599069103452961e-05, 80.0)
8月の江戸川と練馬の月平均気温の検定 (-2.477104608556971, 0.015352998772965724, 80.0)
結果は,1つ目がt統計量,2つ目がp値,3つ目が自由度が帰ってくる.scipy.stats.ttest_ind関数を使った時と全く同じ結果が出ているので,同じ計算をしていることがわかる.