ネットからのCSVファイルの読み込み
Azure Notebookの場合,何もしなくてもURLを書いてやれば,ネットから直接読み込める.
八王子市のオープンデータの一つ,年齢別人口データhttp://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2506.csvを読み込んでみる.
日本の国や自治体が出しているオープンデータは基本的に文字コードがSHIFT_JISなので,指定してやる必要があることに注意.
# 国や自治体の機関が公開しているオープンデータは基本的にExcelからの書き出しであり
# 文字コードがSHIFT_JISなので,
# fileEncodingオプションに'Shift_JIS'を与えてやる
df <- read.csv('http://www.city.hachioji.tokyo.jp/contents/open/002/p005866_d/fil/nenreibetsu_jinkou_2506.csv', fileEncoding='Shift_JIS')
# data.frame形式で出力される
head(df)
head関数は,dataframeの冒頭部分を表示してくれる.
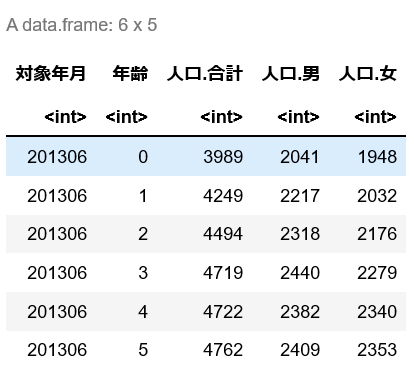
一番上の「対象年月 年齢 人口.合計 人口.男 人口.女」がラベル行であり,これはデータ本体には含まれない.
その次のintが並んでいる行は,その列のデータ型を表す.これもデータ本体には含まれない.
data.frame型の真骨頂は「ラベル指定で取り出せる」ことにある.例えば,
df$'人口.男'
と$列ラベルの形で指定すると,以下のように「人口.男」列がベクトルとして出力される.
2041 2217 2318 2440 2382 2409 2534 2511 2413 2476 2574 2614 2676 2751 2694 2685 2665 2706 3566 4118 4127 4343 3962 3644 3512 3364 3315 3312 3362 3310 3478 3267 3408 3667 3797 3954 3929 4351 4317 4693 4889 4841 4718 4646 4673 4533 4227 3923 4250 3900 3757 3394 3437 3293 3335 3098 3043 3129 3248 3216 3509 3632 3958 4459 4543 4778 4069 2660 3098 3806 3482 3560 3297 3029 2553 2709 2447 2454 2160 1965 1761 1594 1385 1187 1005 929 817 653 563 387 321 227 164 138 98 76 64 36 26 17 9 4 3 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
$はRでは「オブジェクトの中の要素にアクセスする」ことなので,プログラム的にはdata.frameオブジェクトの中に列ごとのオブジェクトがベクトル形式で含まれているようだ.
では行の指定はどうするか.今回のCSVファイルには行にラベルはついていないので(本来なら一番左の列+2番目の列が列名になるはずだが,数字なので整数として読み込まれてしまっている),数字(インデックス)指定で取り出すことになる.
df$'人口.男'[1:3]と書くと,「人口.男』列の1行目~3行目がベクトルとして取り出される.(Rはインデックスが1から始まることに注意.)
2041 2217 2318列ラベルも使わず数字で指定できる.(これはあまり推奨されない.
df[1:3, 4]4列目の1行目から3行目を取り出す,という指定である.4列目は「人口.男」列であるから,前と同じ出力がされる.
2041 2217 2318これまでは,data.frameの一部をベクトルとして取り出したが,もちろん2つ以上の列を同時に抽出することもできる.この場合出力はdata.frame形式になる.
columns <- c('人口.合計','人口.男')
df.sub <- df[, columns]
head(df.sub)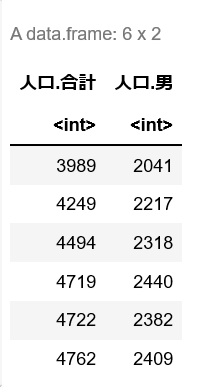
列ラベルのベクトルとして与えてやることに注意する.
グラフの描画
plot(df$'人口.男', type='l')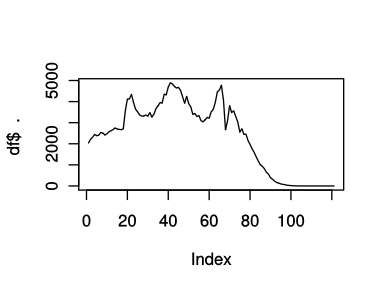
抽出したベクトルをplot関数に渡すと,グラフを書くことができる.この時type='l'は折れ線グラフを表す.(Lineのl)
本来,折れ線グラフを書くときはx軸の系列,y軸の系列の両方を与えるのだが,今回はy軸の系列だけを与えているため,x軸の系列は単に行番号となる.したがって正しくは,
age <- length(df$'年齢')
plot(0:(age-1), df$'人口.男', type='l')というように,「0から年齢列の長さ-1」のx軸系列を作り,その後にy軸の値として人口.男列の値を入れていく,という流れになる.
複数の系列を描画するときには,matplot関数を使う(おそらくmatrix plotの略).matplot関数は行列もしくはdata.frameを取る.
columns <- c('人口.合計', '人口.男', '人口.女')
df.sub <- df[, columns]
matplot(df.sub, type='l')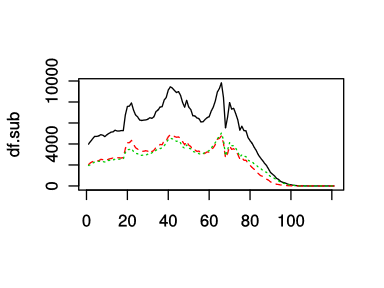
data.frameは「行ごとに対応がある」つまり「同じ行なら対応するデータ」なので,自動的に上記のように同じ行を対応させた形でプロットされる.また色分けも勝手にやってくれる.
線の色に関しては,colオプション(カラーオプション)があらかじめ充てられており,このカラーオプションをベクトルもしくはsequenceで与えることで,自動的に色分けできる.(線種も自動的に分けられている)
columns <- c('人口.合計', '人口.男', '人口.女')
df.sub <- df[, columns]
matplot(df.sub, type='l', col=2:4)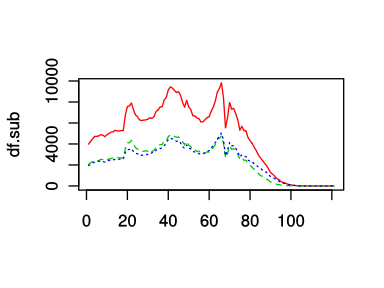
ちなみにcol=1は黒である.
線種の指定はltyオプションで指定する.色は黒で固定したまま,線種を2~4までで指定してみると以下のようになる.ちなみに線種1は直線である.
columns <- c('人口.合計', '人口.男', '人口.女')
df.sub <- df[, columns]
matplot(df.sub, type='l', col=1, lty=2:4)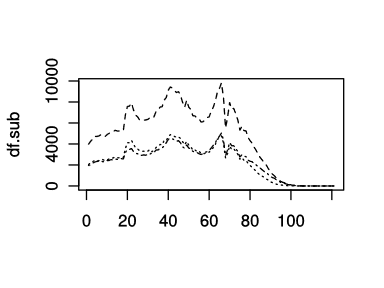
凡例はlegend関数で指定する.場所,凡例のラベルのベクトル,凡例を何列で表示するか,matplotに指定したのと同じカラー,同じ線種,を入れていく.
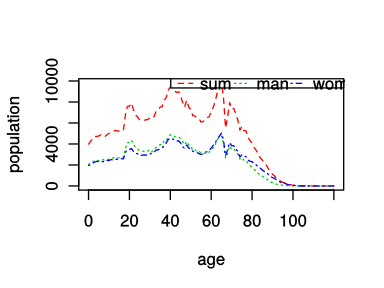
さらに前述したx軸も入れたうえで,x軸のラベルxlabオプション,y軸のラベルylabオプションも入れると,以下のようになる.
age <- length(df$'年齢')
columns <- c('人口.合計', '人口.男', '人口.女')
df.sub <- df[, columns]
matplot(0:(age-1), df.sub, type='l', col=2:4, lty=2:4, xlab='age', ylab='population')
legend("topright", c('sum', 'man', 'woman'), ncol=3, col=2:4, lty=2:4)