本項でもGoogle Colaboratoryを使用する.(もちろんファイル読み込みの部分以外はJupyter Notebookでもよいし,一気にPythonのソースコードをまとめて書いて実行しても問題はない)
今回は,「気温以外のデータ」を使って,太平洋側の都市と日本海側の都市の分類器を作成してみる.
例によって,気象庁オープンデータのページから,
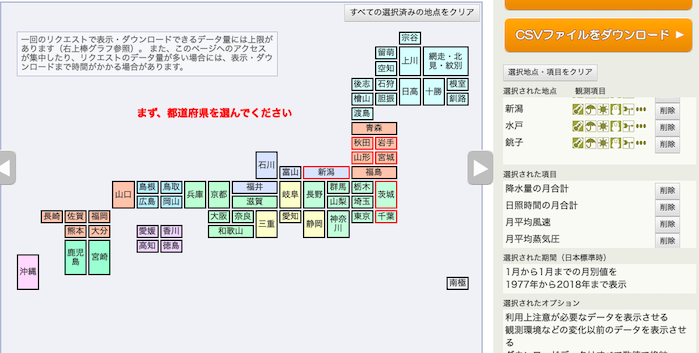
都市は,秋田県→秋田市,岩手県→宮古市,山形県→酒田市,宮城県→石巻市,新潟県→新潟市,茨城県→水戸市,千葉県→銚子市,の順で,それぞれ選択.
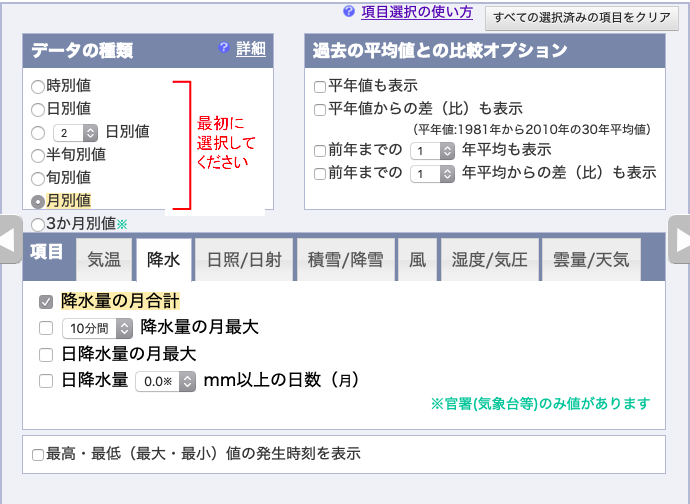
月別の値を選択し,降水量の月合計,
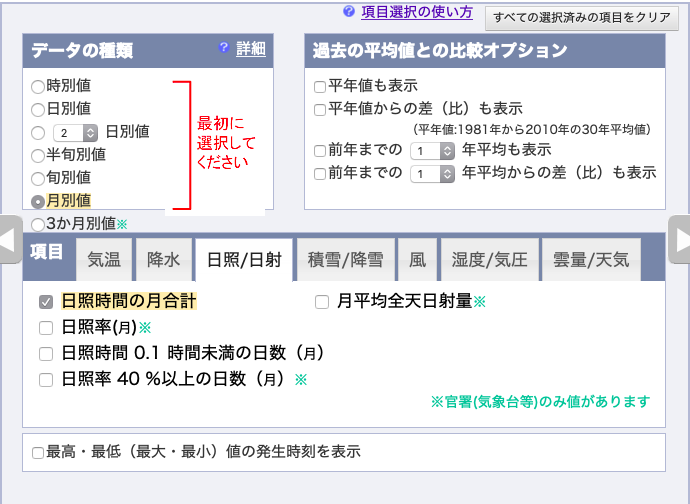
日照時間の月合計,
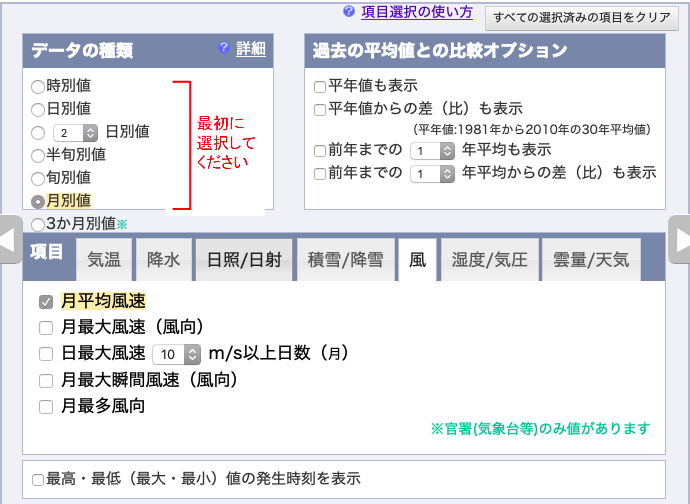
月平均風速,
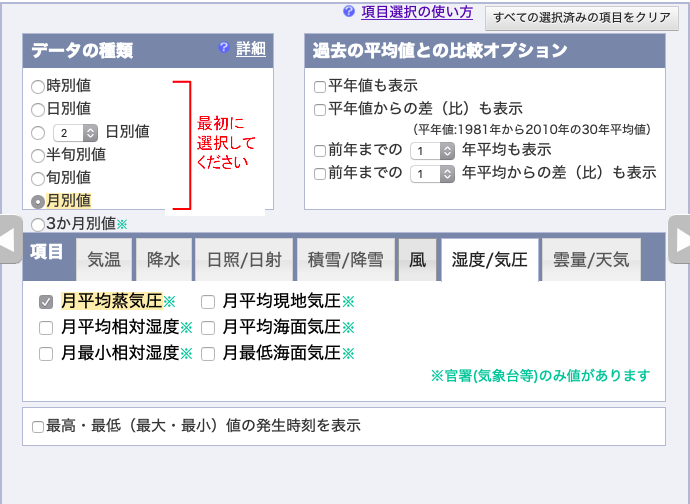
湿度/気圧の月平均蒸気圧,を選択し,
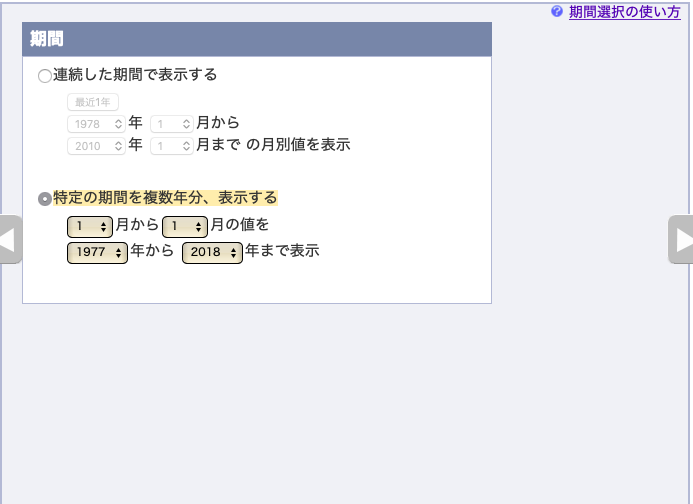
1977年〜2018年の「1月」のデータをダウンロードする.
表示オプションはデフォルト.地点の順番と,項目の順番を確認すること.
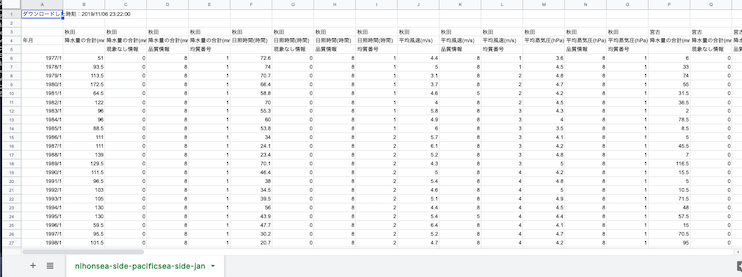
ダウンロードしたCSVはこんな見た目になる.
線形二項分類
線形分類(Linear Classification)とは,2つのカテゴリが入っているデータの集合の真ん中に一本直線を引くことで,カテゴリ分けする境目を定め,予測したいデータが入ってきた時に,どちらかに分類する問題である.もちろん人間が一本線を引くことで行うこともできるが,これを機械学習で行う.
入力するデータが2次元,例えば「降水量,日照時間」だった場合には,カテゴリ分けする境目は「直線」になるが,「降水量,日照時間,湿度」のように3次元になると「2次元平面」になり,「降水量,日照時間,湿度,風速」のように4次元だと「3次元超平面」になる.
3次元空間上の平面ぐらいは平面に表示するグラフでなんとか表示できるものの,4次元以上は無理なので,写像をするか「4次元の線形の式」として理解するしかない.
本項では,線形Support Vector Machine(Linear SVM)と,ロジスティック回帰(Logistic Regression)による,分類器というか,つまり直線に必要な「係数」および「切片」を学習する.
ロジスティック回帰は「回帰」と名がついているが,分類問題に使う.分ける直線を学習するので「線形回帰」とも言えるので,この名前がついている.
ダミー変数とカテゴリ変数
日本海側と太平洋側の年を分類すると書いたが,SVMやロジスティック回帰で機械学習するためには,これを数字に直さなければならない.もちろん太平洋側と日本海側は大小の比較ができないなど「値」としては,意味がないわけで,ここでは太平洋側を0,日本海側を1として表すことにする.
このように,その要素の有無で0と1の2値で表現される変数,その大小や差に意味がないものを「ダミー変数」と呼ぶ.(回帰分析でもダミー変数を使うことができる.)
例えば北海道の都市のように「太平洋側,日本海側,オホーツク海側」のように3つ以上の状態があり,2値で表すことができないもの,つまり「0, 1, 2, 3...などの状態が複数あり,かつその数字が大小の意味を持ってない場合」は,カテゴリ変数と呼ぶ
カテゴリ変数は二項分類つまりここでおこなような「AとBのどっち?」の問題では扱えないので,カテゴリ変数で表現している内容を,要素に分けて,要素の有無で表現,つまり複数のダミー変数に直すなどの方法をとる.
コード例
1つ目のセル.例によってCSVをColabへ読み込む.
from google.colab import files
uploaded = files.upload()
2つ目のセル.品質情報などの列が不要なので削除.
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
df = pd.read_csv('nihonsea-side-pacificsea-side-jan.csv', encoding='SHIFT-JIS', header=1)
# 抜き出す
for a_column in ['秋田', '宮古', '酒田', '石巻', '新潟', '水戸', '銚子']:
# それぞれ
# 降水量の合計(mm),降水量の合計(mm),降水量の合計(mm),降水量の合計(mm), 日照時間(時間),日照時間(時間),日照時間(時間),日照時間(時間), 平均風速(m/s),平均風速(m/s),平均風速(m/s),平均蒸気圧(hPa),平均蒸気圧(hPa),平均蒸気圧(hPa),
# で並んでいて,一つの地点につき,
# (空), 現象なし情報, 品質情報, 均質番号, (空), 現象なし情報, 品質情報, 均質番号, (空), 品質情報, 均質番号, (空), 品質情報, 均質番号
# の(空)以外の場所が余計なので,削除
# 7地点分回す
for i in range(1, 7, 1):
# 各地点の落とす列の列番号を指定(0~)
if i in [1, 2, 3, 5, 6, 7, 9, 10, 12, 13]:
df = df.drop(a_column + '.' + str(i), axis=1)
# 年月の列を落とす
df = df.drop(1)
# DataFrameの中に欠損値がある場合は,0.0を代わりに入れておく
df = df.fillna(0)
df.head()
3つ目のセル.ダミー変数を入れて,各都市のデータの列を繋いで,一つのデータフレームにする.
# グラフ表示するためにローマ字ラベルを作っておく
#np.arrayはenumerateでは回せないので, listのままにしておく
city_label_list = (['Akita', 'Miyako', 'Sakata', 'Ishinomaki', 'Niigata', 'Mito', 'Choshi'])
# その要素の有無で0と1の2値で表現される変数を「ダミー変数」と呼ぶ
# 0, 1, 2, 3...などの状態が複数あり,かつその数字が大小の意味を持ってない場合は,カテゴリ変数と呼ぶ
# カテゴリ変数は判別問題などで扱えないので,
# カテゴリ変数で表現している内容を,要素に分けて,要素の有無で表現,つまり複数のダミー変数に直す
# 今回は太平洋側と日本海側の2値なので,ダミー変数:太平洋側が0, 日本海側が1
sea_side_label = np.array([1, 0, 1, 0, 1, 0, 0])
# 選んだ都市の
# average_wind_speed: 1月の平均風速
# daylight_hours: 1月の日照時間
# average_humidity: 1月の平均湿度
# precipitation: 1月の降水量
# として,それぞれ42年分*太平洋側,日本海側の2年ずつを,1つ配列としてくっつける
# 42年分のラベルを繋げておく (42年分*全部の都市)
city_label_in_repeat = np.repeat(city_label_list, 42)
sea_side_label_in_repeat = np.repeat(sea_side_label, 42)
# データをつなげる
# まず最初に空の配列を作っておいて,
precipitation = np.array([], dtype=np.float)
daylight_hours = np.array([], dtype=np.float)
average_wind_speed = np.array([], dtype=np.float)
average_humidity = np.array([], dtype=np.float)
# 選んだ都市の,1月の平均風速,1月の日照時間,1月の平均湿度,1月の降水量を
# それぞれ1つの配列につなぐ
for i, a_city in enumerate(city_label_list):
precipitation = np.concatenate((precipitation, df.iloc[1:, 1+(i*4)]))
daylight_hours = np.concatenate((daylight_hours, df.iloc[1:, 1+(i*4)+1]))
average_wind_speed = np.concatenate((average_wind_speed, df.iloc[1:, 1+(i*4)+2]))
average_humidity = np.concatenate((average_humidity, df.iloc[1:, 1+(i*4)+3]))
# vstackで重ねて,配列の次元を入れ替えて,DataFrameにしておく
df_sea_side_city = pd.DataFrame(np.vstack([city_label_in_repeat, sea_side_label_in_repeat, precipitation.astype(np.float), daylight_hours.astype(np.float), average_wind_speed.astype(np.float), average_humidity.astype(np.float), ]).transpose())
# DataFrameの列名をつけておく
df_sea_side_city = df_sea_side_city.rename(columns={0:'都市名', 1:'太平洋側日本海側ダミー変数', 2:'1月の降水量', 3:'1月の日照時間', 4:'1月の平均風速', 5:'1月の平均湿度'})
# DataFrameの冒頭を確認
df_sea_side_city.head()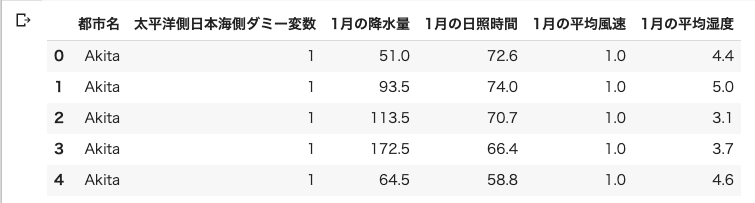
4つ目のセル.訓練データとテストデータにランダムに分ける.訓練データで学習し,テストデータを正確に分類できれば,その線形分類は有用だと言える.
from sklearn.model_selection import train_test_split
# 線形分類は,Xは説明変数多数の行列,Yは0or1(この場合太平洋側か日本海側かのダミー変数)が入った1次元配列を取る
y_whole = df_sea_side_city.iloc[:, 1].values
x_whole = df_sea_side_city.iloc[:, 2:].values
# yを1次元配列にする
y_whole = np.ravel(y_whole)
# 訓練データとテストデータに分ける
# 実行する度に訓練データとテストデータに選ばれる行がランダムで変わる
x_train, x_test, y_train, y_test = train_test_split(x_whole, y_whole)5つ目のセル.分類する線形SVMを学習する
# 線形SVMで分類するための学習
from sklearn.svm import LinearSVC
from sklearn import metrics
svm_model = LinearSVC(C=1.0)
svm_model.fit(x_train, y_train)
svm_y_predict = svm_model.predict(x_test)
svm_accuracy_score = metrics.accuracy_score(y_test, svm_y_predict)
print('svmの正答率', svm_accuracy_score)
# 係数がこの中に入っている.この係数で表される4次元空間の平面で切るとうまく分類できる,という意味
print('分離平面の係数', svm_model.coef_[0])
print('分離平面の切片', svm_model.intercept_[0])
# 分離平面の係数をもうちょっとわかりやすく表示してみる
svm_coef_df = pd.DataFrame([df_sea_side_city.columns[2:], svm_model.coef_[0]]).T
# DataFrame.Tはnumpyのtransposeに相当し,配列の次元を入れ替える
print(svm_coef_df)5つ目のセルの結果は以下のようになる.
svmの正答率 0.9864864864864865
分離平面の係数 [ 0.04655286 -0.01708395 0.03802717 -0.03184421]
分離平面の切片 -1.2240700054688827
0 1
0 1月の降水量 0.0465529
1 1月の日照時間 -0.0170839
2 1月の平均風速 0.0380272
3 1月の平均湿度 -0.03184426つ目のセル.学習に使わなかった別の地点のデータから,太平洋側,日本海側のどちらかを予測する.
# 鳥取県境(日本海側),静岡県石廊崎(太平洋側)の2018年1月のデータを入れてみて,ちゃんと分類できるか検証する.
# 境のデータ 降水量191.5(mm), 日照時間58.1(時間), 平均風速2.6(m), 平均蒸気圧6.3(hPa),
# 石廊崎のデータ 降水量 93.5(mm), 日照時間188.6(時間), 平均風速6.8(m), 平均蒸気圧6.6(hPa)
sakaiX = np.array([[191.5, 58.1, 2.6, 6.3]], dtype=np.float)
irouzakiX = np.array([[93.5, 188.6, 6.8, 6.6]], dtype=np.float)
print('境の2018年1月のデータから予測した結果', svm_model.predict(sakaiX))
print('石廊崎の2018年1月のデータから予測した結果', svm_model.predict(irouzakiX))6つ目のセルの結果は以下のようになる.境が1,石廊崎が0と判断されているので,学習したSVMの分類はそれなりに正しいようだ.もちろんさらに学習の制度を検証するために,他の都市,他の地点のデータを突っ込んで,確かめてみるのも良い.
境の2018年1月のデータから予測した結果 [1.]
石廊崎の2018年1月のデータから予測した結果 [0.]7つ目のセル.今度は全く同じ訓練データとテストデータを,ロジスティック回帰で分類するために学習する
from sklearn.linear_model import LogisticRegression
# X, Yの訓練データでロジスティック回帰を学習する
log_model = LogisticRegression()
log_model.fit(x_train, y_train)
# 学習済みのモデルにXテストデータをつっこみ,Yを予測し,観測データと比較
log_y_predict = log_model.predict(x_test)
log_accuracy_score = metrics.accuracy_score(y_test, log_y_predict)
print('ロジスティック回帰の正答率:', log_accuracy_score)
# 係数がこの中に入っている.この係数で表される4次元空間の平面で切るとうまく分類できる,という意味
print('分離平面の係数', log_model.coef_[0])
print('分離平面の切片', log_model.intercept_[0])
# 同じく分離平面の係数をもうちょっとわかりやすく表示してみる
log_coef_df = pd.DataFrame([df_sea_side_city.columns[2:], log_model.coef_[0]]).T
print(log_coef_df)7つ目のセルの結果は以下のようになる.傾き(係数)や切片は線形SVMと異なっているが,学習はちゃんとできているようだ.
ロジスティック回帰の正答率: 0.9459459459459459
分離平面の係数 [ 0.26298817 -0.18462974 0.25403575 -0.32331834]
分離平面の切片 -3.3614051554580233
0 1
0 1月の降水量 0.262988
1 1月の日照時間 -0.18463
2 1月の平均風速 0.254036
3 1月の平均湿度 -0.3233188つ目のセル.同じくロジスティック回帰に,鳥取県境と,静岡県石廊崎の2018年1月のデータを突っ込んで,予測させてみる.
sakaiX = np.array([[191.5, 58.1, 2.6, 6.3]], dtype=np.float)
irouzakiX = np.array([[93.5, 188.6, 6.8, 6.6]], dtype=np.float)
print('境の2018年1月のデータから予測した結果', log_model.predict(sakaiX))
print('石廊崎の2018年1月のデータから予測した結果', log_model.predict(irouzakiX))8つ目のセルの結果は以下のようになる.前述の通り線形SVMと傾きと切片は異なるものの,ロジスティック回帰でもちゃんと分類されているようだ.
境の2018年1月のデータから予測した結果 [1.]
石廊崎の2018年1月のデータから予測した結果 [0.]今回はちゃんと分類できているが,やはり訓練データとテストデータの分け方によって予測精度にだいぶ差が出る.SVMの時と同じく,「日本海側の都市を誤って太平洋側」と判別している率が高い.
つまり,1月の降水量,1月の日照時間,1月の風速平均,1月の湿度の4つの観測値は,日本海側と太平洋側を判定するのには不十分である,と言える.別の観測値を使って予測精度を上げてみよう.